Lakehouse
Playground for Lakehouse (Iceberg, Hudi, Spark, Flink, Trino, DBT, Airflow, Kafka, Debezium CDC)
- Kafka UI: http://localhost:8088 - Kafka Connect UI: http://localhost:8089 - Trino: http://localhost:8889 - Airflow (`airflow` / `airflow`) : http://localhost:8080 - Local S3 Minio (`minio` / `minio123`): http://localhost:9000 - Flink Job Manager UI (Docker): http://localhost:8082 - Flink Job Manager UI (LocalApplication): http://localhost:8081 - PySpark Jupyter Notebook (Iceberg): http://localhost:8900 - PySpark Jupyter Notebook (Hudi): http://localhost:8901 - Spark SQL (Iceberg): `docker exec... The project is written primarily in Kotlin, first published in 2023. Key topics include: airflow, cdc, dbt, debezium, docker.
Lakehouse Playground
![]()
Supported Data Pipeline Components
| Pipeline Component | Version | Description |
|---|---|---|
| Trino | 425+ | Query Engine |
| DBT | 1.5+ | Analytics Framework |
| Spark | 3.3+ | Computing Engine |
| Flink | 1.16+ | Computing Engine |
| Iceberg | 1.3.1+ | Table Format (Lakehouse) |
| Hudi | 0.13.1+ | Table Format (Lakehouse) |
| Airflow | 2.7+ | Scheduler |
| Jupyterlab | 3+ | Notebook |
| Kafka | 3.4+ | Messaging Broker |
| Debezium | 2.3+ | CDC Connector |
Getting Started
Execute compose containers first.
bash# Use `COMPOSE_PROFILES` to select the profile COMPOSE_PROFILES=trino docker-compose up; COMPOSE_PROFILES=spark docker-compose up; COMPOSE_PROFILES=flink docker-compose up; COMPOSE_PROFILES=airflow docker-compose up; # Combine multiple profiles COMPOSE_PROFILES=trino,spark docker-compose up; # for CDC environment (Kafka, ZK, Debezium) make compose.clean compose.cdc # for Stream environment (Kafka, ZK, Debezium + Flink) make compose.clean compose.stream
Then access the lakehouse services.
- Kafka UI: http://localhost:8088
- Kafka Connect UI: http://localhost:8089
- Trino: http://localhost:8889
- Airflow (
airflow/airflow) : http://localhost:8080 - Local S3 Minio (
minio/minio123): http://localhost:9000 - Flink Job Manager UI (Docker): http://localhost:8082
- Flink Job Manager UI (LocalApplication): http://localhost:8081
- PySpark Jupyter Notebook (Iceberg): http://localhost:8900
- PySpark Jupyter Notebook (Hudi): http://localhost:8901
- Spark SQL (Iceberg):
docker exec -it spark-iceberg spark-sql - Spark SQL (Hudi):
docker exec -it spark-hudi spark-sql - Flink SQL (Iceberg):
docker exec -it flink-jobmanager flink-sql-iceberg - Flink SQL (Hudi):
docker exec -it flink-jobmanager flink-sql-hudi;
CDC Starter kit
bash# Run cdc-related containers make compose.cdc; # Register debezium mysql connector using Avro Schema Registry make debezium.register.customers; # Register debezium mysql connector using JSON Format make debezium.register.products;
Running Flink Applications
Flink supports Java 11 but uses Java 8 due to its SQL (Hive) dependency.
The Flink SQL Application within this project is written in Kotlin for SQL Readability.
You can run it as an Application in IDEA. (it is not a Kotlin Application)
For Flink Application, the required dependencies are already included within the Production Docker Image or EMR cluster.
Therefore, they are set as 'Provided' dependencies in the Maven project, so to run them locally,
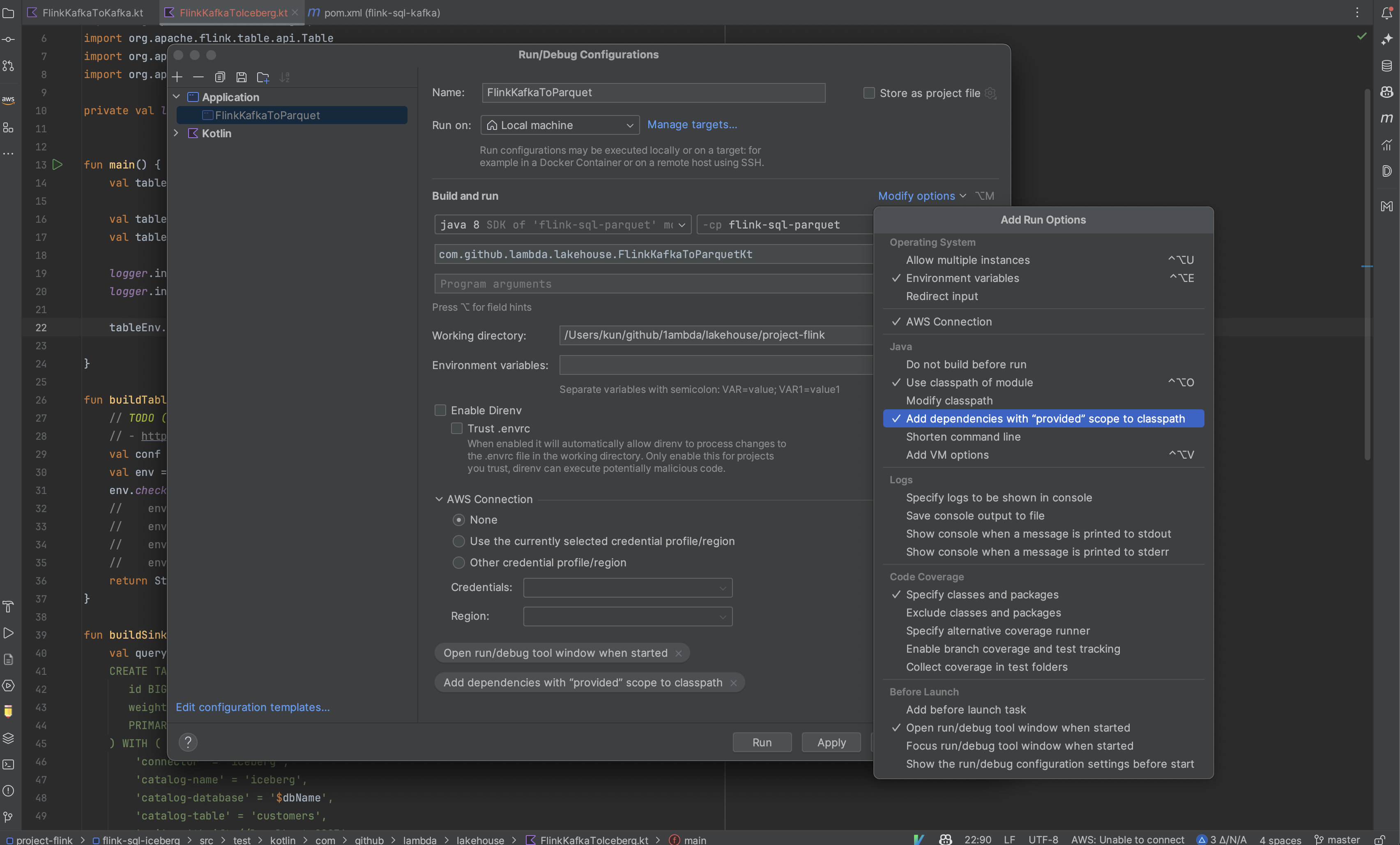
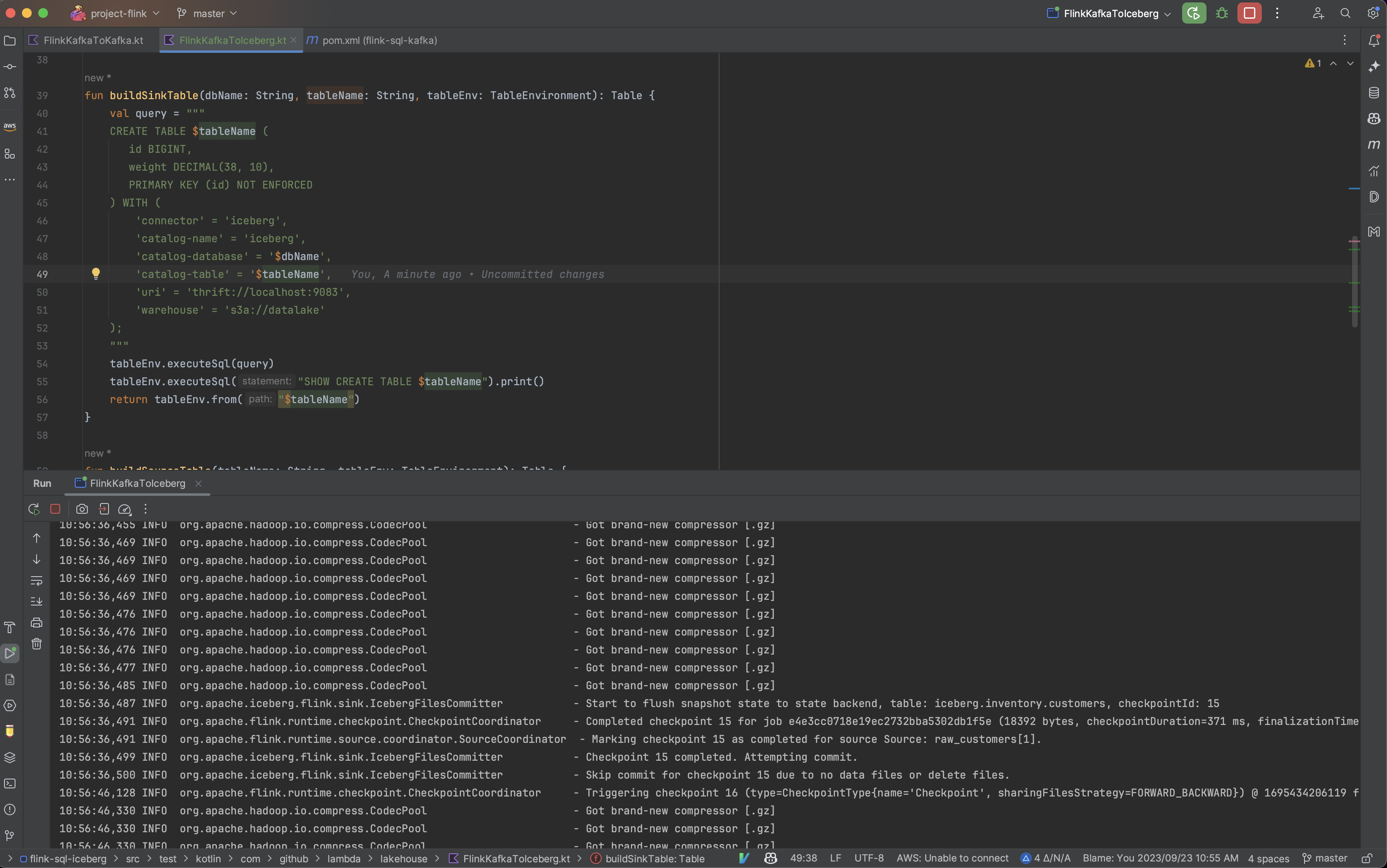
you can include the Add dependencies with "provided" scope to classpath" IDEA option as shown in the screenshot below.
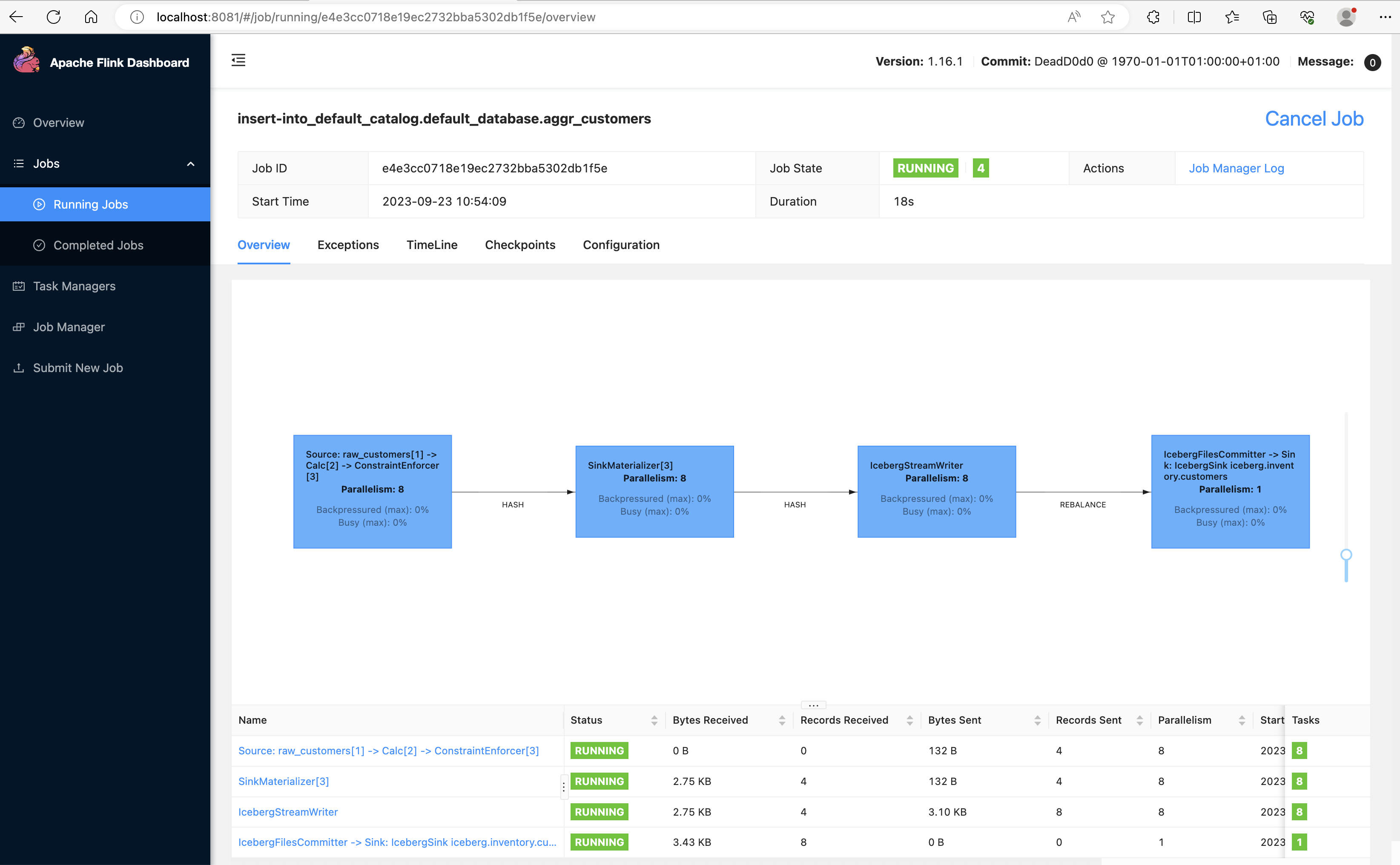
After running the Local Flink Application, you can access the Flink Job Manager UI from localhost:8081.
DBT Starter kit
bash# Run trino-related containers make compose.dbt; # Prepare iceberg schema make trino-cli; $ create schema iceberg.staging WITH ( LOCATION = 's3://datalake/staging' ); $ create schema iceberg.mart WITH ( LOCATION = 's3://datalake/mart' ); # Execute dbt commands locally cd dbts; dbt deps; dbt run; dbt test; dbt docs generate && dbt docs serve --port 8070; # http://localhost:8070 # Select dbt-created tables from trino-cli make trino-cli; $ SELECT * FROM iceberg.mart.aggr_location LIMIT 10; $ SELECT * FROM iceberg.staging.int_location LIMIT 10; $ SELECT * FROM iceberg.staging.stg_nations LIMIT 10; $ SELECT * FROM iceberg.staging.stg_regions LIMIT 10; # Execute airflow dags for dbt make airflow.shell; airflow dags backfill dag_dbt --local --reset-dagruns -s 2022-09-02 -e 2022-09-03;
Screenshots
Flink Job Manager UI
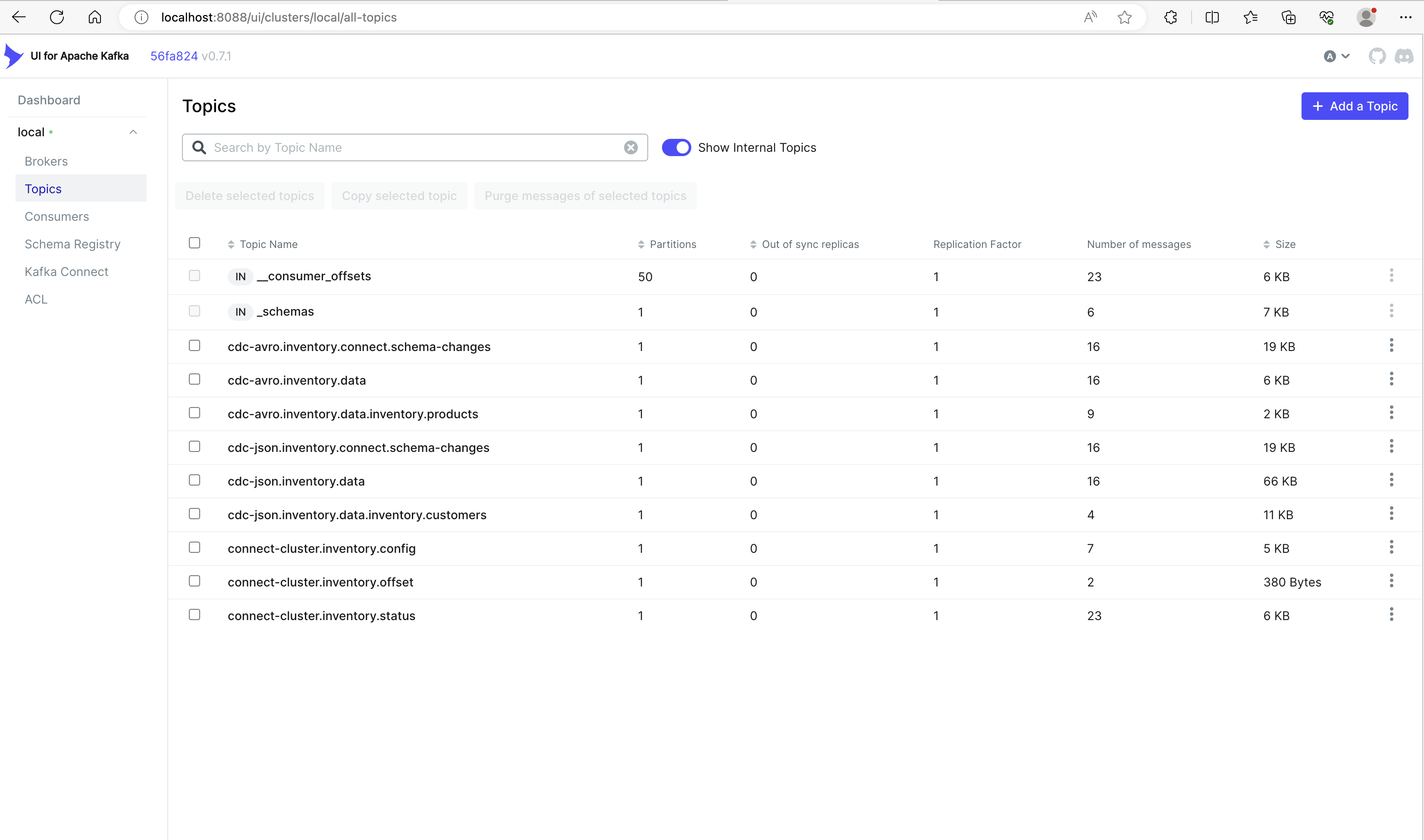
Kafka UI
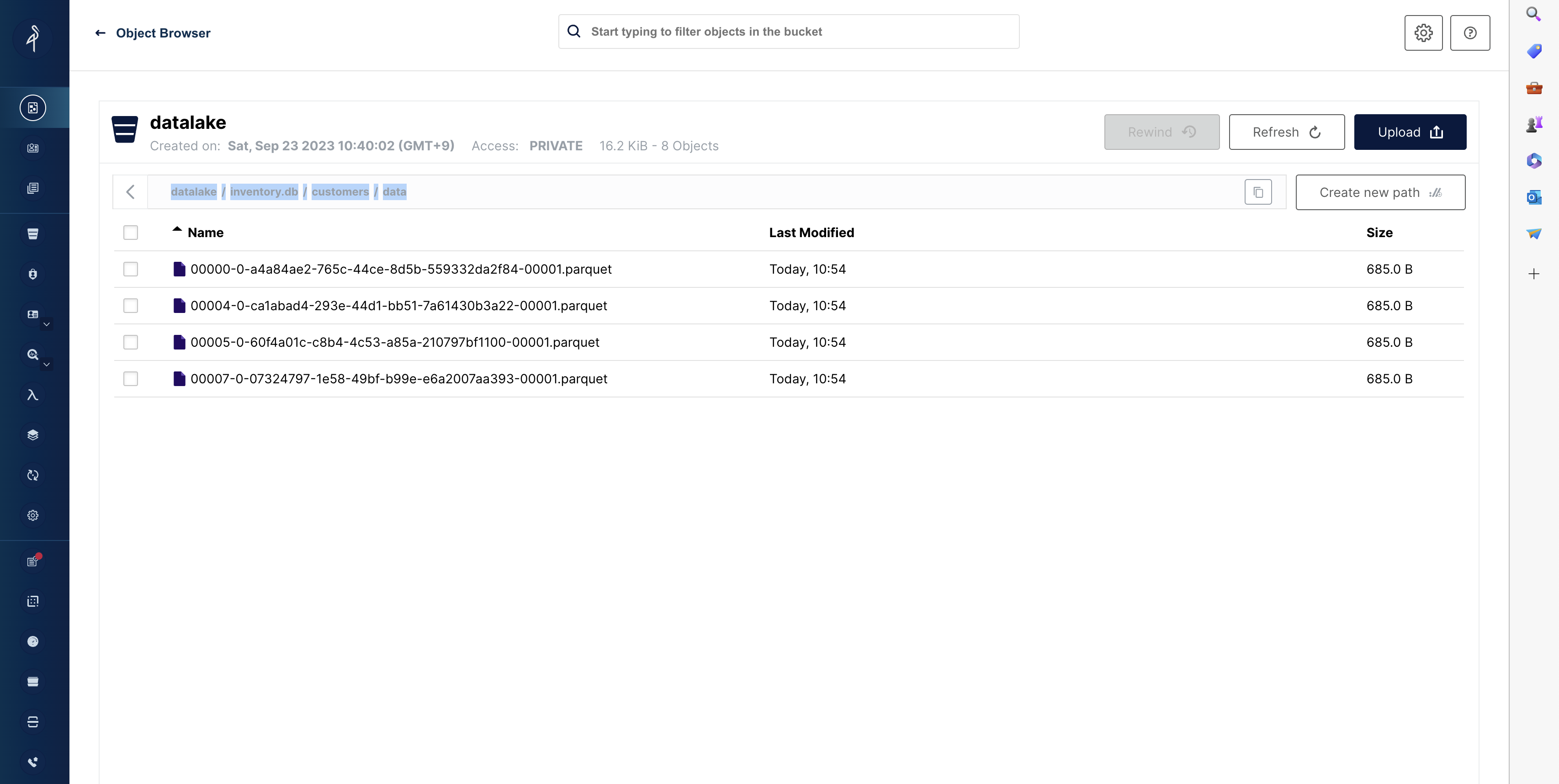
Minio UI
Running Local Flink Application in IDEA
Contributors
Showing top 1 contributor by commit count.

Related Repositories

apache/airflow
Apache Airflow - A platform to programmatically author, schedule, and monitor workflows

argoproj/argo-workflows
Workflow Engine for Kubernetes
apache/dolphinscheduler
Apache DolphinScheduler is the modern data orchestration platform. Agile to create high performance workflow with low-code

orchest/orchest
Build data pipelines, the easy way 🛠️

jghoman/awesome-apache-airflow
Curated list of resources about Apache Airflow

puckel/docker-airflow
Docker Apache Airflow