A evolve
The official repository of "Position: Agentic Evolution is the Path to Evolving LLMs".
> **The PyTorch for Agentic AI.** > A-Evolve is an open-source infrastructure that evolves *any* agent, across *any* domain, using *any* evolution algorithm — with zero human intervention. The project is written primarily in Python, first published in 2026. Key topics include: agents, continual-learning, llm-agents, recursive-self-improvement, self-evolving.
A-Evolve 🧬: The Universal Infrastructure for Self-Improving Agents
![]()
![]()
![]()

The PyTorch for Agentic AI.
A-Evolve is an open-source infrastructure that evolves any agent, across any domain, using any evolution algorithm — with zero human intervention.
Quick Start | News | Benchmark Highlights | Architecture & Design | Contribution
</p>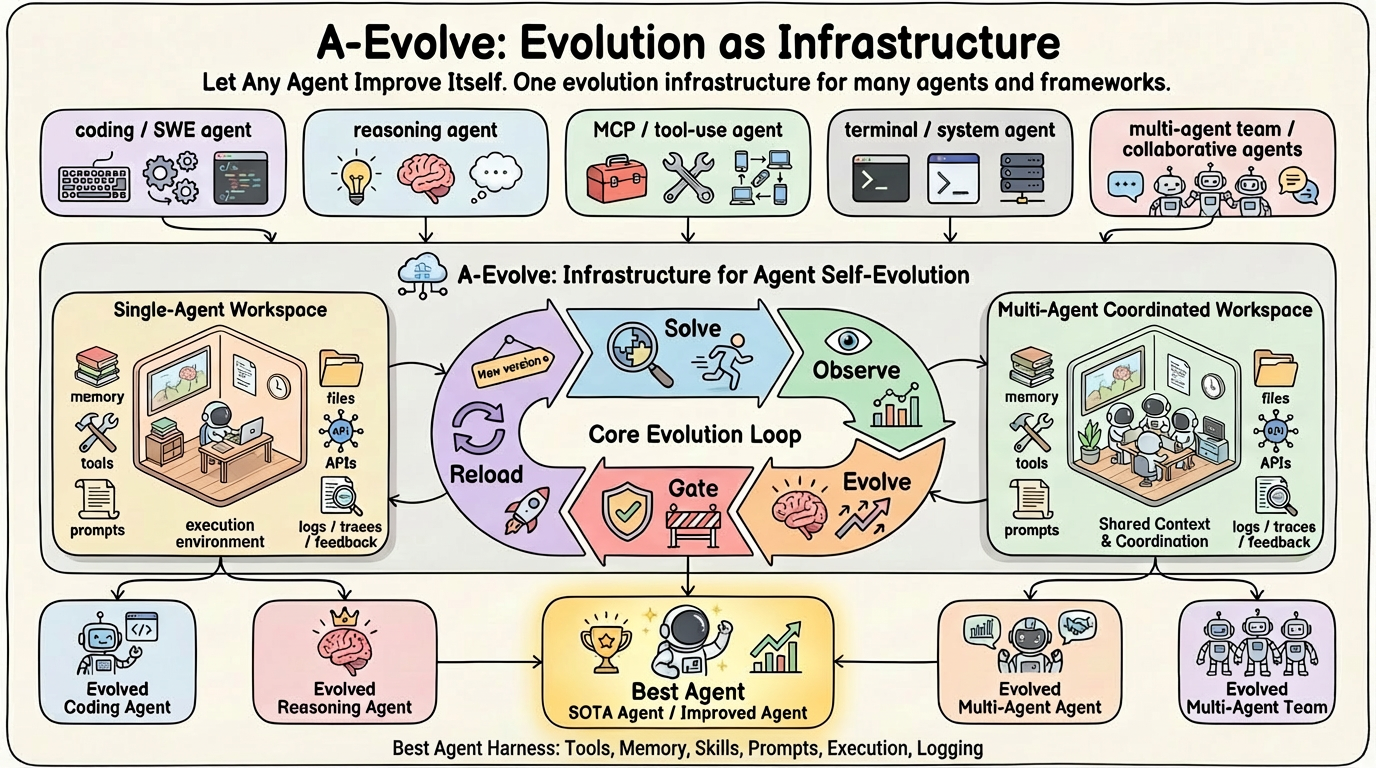
What Does A-Evolve Do?
You provide a Base Agent. A-Evolve returns a SOTA Agent. 3 lines of code. 0 hours of manual harness
engineering. One infra, any domain, any evolution algorithm.
pythonimport agent_evolve as ae evolver = ae.Evolver(agent="./my_agent", benchmark="swe-verified") results = evolver.run(cycles=10)
Benchmark Highlights
By applying our open-source reference evolution algorithms to a base Claude Opus-4.6 model with zero manual harness engineering, A-Evolve pushed agents into top-tier performance across four diverse benchmarks:
<table> <tr> <td align="center" width="23%"> <h3>🟢 MCP-Atlas</h3> <img src="https://img.shields.io/badge/79.4%25-10b981?style=for-the-badge&labelColor=065f46" /> <br/><br/> <strong>🥇 #1</strong><br/> <sub>Baseline → <strong>79.4%</strong> (+3.4pp)</sub> </td> <td align="center" width="23%"> <h3>🔵 SWE-bench Verified</h3> <img src="https://img.shields.io/badge/76.8%25-2563eb?style=for-the-badge&labelColor=1e3a5f" /> <br/><br/> <strong>~#5</strong><br/> <sub>Baseline → <strong>76.8%</strong> (+2.6pp)</sub> </td> <td align="center" width="23%"> <h3>🟣 Terminal-Bench 2.0</h3> <img src="https://img.shields.io/badge/76.5%25-7c3aed?style=for-the-badge&labelColor=3b1d6e" /> <br/><br/> <strong>~#7</strong><br/> <sub>Baseline → <strong>76.5%</strong> (+13.0pp)</sub> </td> <td align="center" width="23%"> <h3>🟡 SkillsBench</h3> <img src="https://img.shields.io/badge/34.9%25-d97706?style=for-the-badge&labelColor=78350f" /> <br/><br/> <strong>#2</strong><br/> <sub>Baseline → <strong>34.9%</strong> (+15.2pp)</sub> </td> </tr> <tr> <td align="center" width="23%"> <h3>🟢 ARC-AGI</h3> <img src="https://img.shields.io/badge/12.3%25-10b981?style=for-the-badge&labelColor=065f46" /> <br/><br/> <strong>🥇 #2 Community Leaderboard</strong><br/> <sub>Baseline → <strong>12.3%</strong> (+2.2pp)</sub> </td> <td align="center" width="23%"> <h3>🔵 OSWorld</h3> <img src="https://img.shields.io/badge/69.6%25-2563eb?style=for-the-badge&labelColor=1e3a5f" /> <br/><br/> <strong>—</strong><br/> <sub>Baseline → <strong>69.6%</strong> (+3.9pp)</sub> </td> <td align="center" width="23%"> <h3>🟣 SWE-bench Lite</h3> <img src="https://img.shields.io/badge/67.0%25-7c3aed?style=for-the-badge&labelColor=3b1d6e" /> <br/><br/> <strong>Evolved</strong><br/> <sub>63.7 → <strong>67.0%</strong> (+3.3pp)</sub> </td> <td align="center" width="23%"> <h3>🟡 τ-bench</h3> <img src="https://img.shields.io/badge/77.0%25-d97706?style=for-the-badge&labelColor=78350f" /> <br/><br/> <strong>Evolved</strong><br/> <sub>72.7 → <strong>77.0%</strong> (+4.3pp)</sub> </td> </tr> <tr> <td align="center" width="23%"> <h3>🟢 CL-Bench</h3> <img src="https://img.shields.io/badge/34.0%25-10b981?style=for-the-badge&labelColor=065f46" /> <br/><br/> <strong>Evolved</strong><br/> <sub>29.5 → <strong>34.0%</strong> (+4.5pp)</sub> </td> <td align="center" width="23%"> <h3>🔵 WebArena-Infinity</h3> <img src="https://img.shields.io/badge/76.3%25-2563eb?style=for-the-badge&labelColor=1e3a5f" /> <br/><br/> <strong>Evolved</strong><br/> <sub>72.5 → <strong>76.3%</strong> (+3.8pp)</sub> </td> </tr> </table>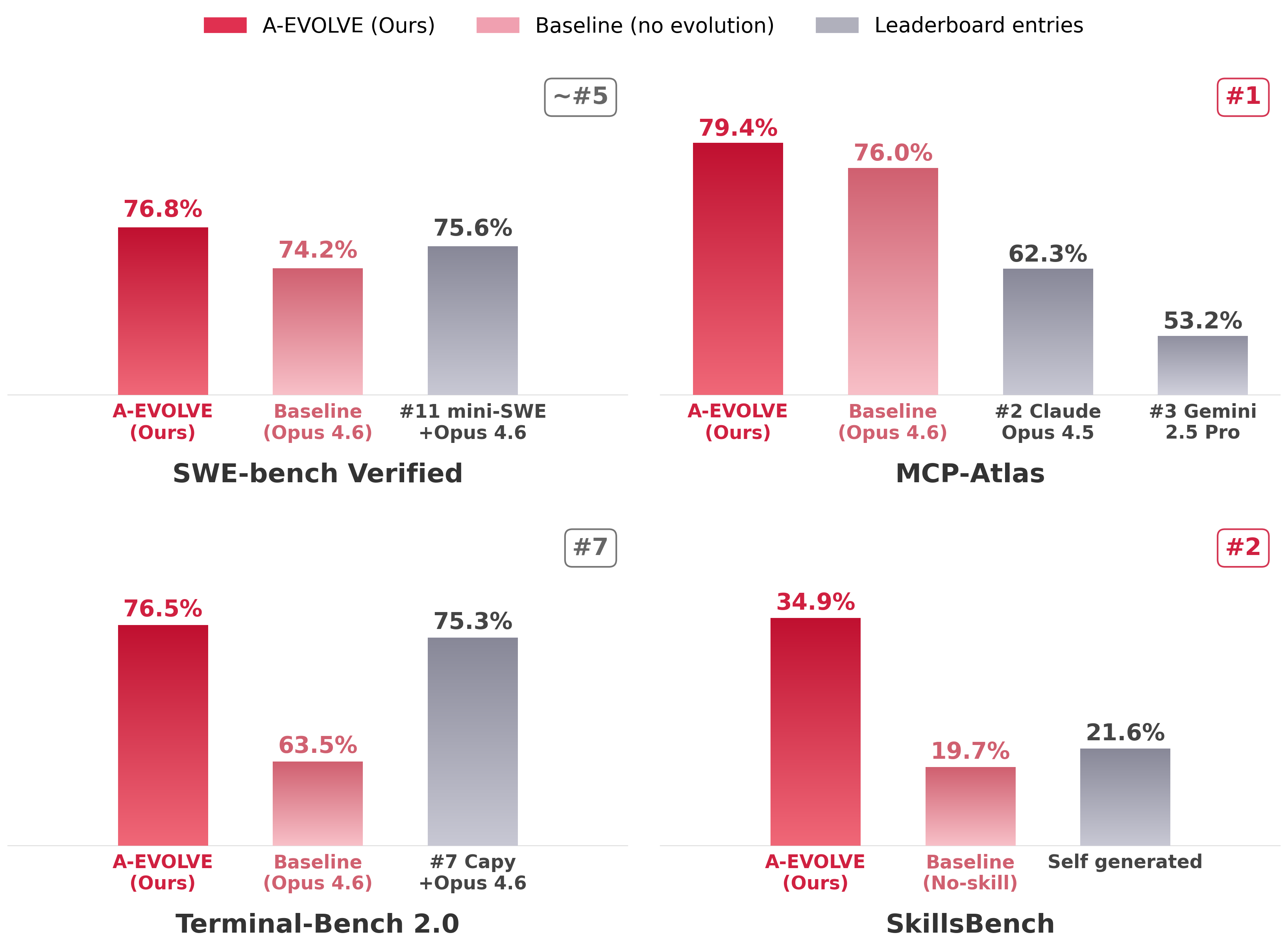
All results achieved with a single Claude Opus-4.6 base model, evolved using A-Evolve's sample algorithms. 0 hours of human harness engineering. Data checked March 2026.
News
- 6/11 New Tech Report on Auto-post-training, A-Evolve-Training: Autonomous Post-Training of a 30B Model. We bulit an AI system that ran the post-training loop for a 30B model — with no human in the loop. Four self-directed rounds on GPU clusters. The autonomously produced model placed 8th of ~4,000 on NVIDIA's Nemotron Reasoning Challenge — one point behind the top human team. The same autonomous system has since post-trained the 120B and 550B Nemotron models. This is, to the best of our knowledge, first public evidence at this scale.
- 6/1 New Research Paper, Adaptive Auto-Harness: Sustained Self-Improvement for Agentic System Deployment on Open-Ended Task Streams (arXiv 2606.01770). We address the brittleness of traditional auto-harness systems when moving from fixed benchmarks to open-ended, shifting task streams. We introduce Adaptive Auto-Harness, a framework that significantly outperforms five existing auto-harness baselines across prediction-market, security-competition, and event-forecasting streams.
- 5/30 New Research Paper, Harness Updating Is Not Harness Benefit: Disentangling Evolution Capabilities in Self-Evolving LLM Agents (arXiv 2605.30621).Tested across 7 evolver models (Opus-4.6, Sonnet-4.6, Qwen-3.5-9B, GPT-OSS-120B, etc.) × 6 solver agents × 3 agentic benchmarks (SWE-bench Verified, MCP-Atlas, SkillsBench), we answered which model produced the best harness update and which models benefits the most from harness update.
- 05/04 New Benchmark Results, A-Evolve added results on ARC-AGI-3, evolving a multi-agent system to be more powerful on solving difficult tasks like ARC-AGI-3. Improving performance from 10% to 12%.
- 04/20 New Algorithm Drop, A-Evolve added new evolutionary algorithm GEPA, submitted by the GEPA team.
- 04/10 Integration, A-Evolve is officially integrated into Orch-Research Skills Library, along with others including AutoResearch, OpenRLHF, DeepSpeed, SGLang
- 04/07 New Agent Drop, We added recently leaked public ClawCode (Claude Code), took the evolution harness + skills we learned on Terminal-Bench 2.0 (TB2) and directly transplanted them onto the ClawCode. Result on TB2: baseline 67.8% → 72.9% (+5.1pp uplift)
- 04/03 New Algorithm Drop, A-Evolve added new evolutionary algorithm Meta-Harness
- 03/30 Integration, A-Evolve is officially integrated into AutoResearchClaw
- 03/25 🚀 Open-source A-Evolve, the universal infrastructure for developing and testing evolving algorithms.
- 03/25 📊 Open-source 4 evolving algorithms developed with A-Evolve, achieving SOTA (#1, ~#5, ~#7, #2) on MCP-Atlas, SWE-bench Verified, Terminal-Bench 2.0, and SkillsBench.
- 02/17 📄 Release the official implementation of Position: Agentic Evolution is the Path to Evolving LLMs (arXiv 2602.00359).
We are evolving fast! Support our research by leaving a ⭐.
What Does an Evolved Agent Look Like?
A-Evolve mutates real files in the workspace. Here's a before/after from our MCP-Atlas evolution:
<table> <tr> <th width="50%">Before (Seed Workspace)</th> <th width="50%">After (Evolved — 79.4% on MCP-Atlas)</th> </tr> <tr> <td>mcp_agent/
├── manifest.yaml
├── prompts/system.md ← 20 lines, generic
├── skills/ ← empty
└── memory/ ← empty
mcp_agent/
├── manifest.yaml
├── prompts/system.md ← 20 lines, unchanged
├── skills/
│ ├── entity-verification/SKILL.md ← NEW
│ ├── search-iteration/SKILL.md ← NEW
│ ├── multi-requirement/SKILL.md ← NEW
│ ├── code-execution/SKILL.md ← NEW
│ └── conditional-handler/SKILL.md ← NEW
└── memory/
└── episodic.jsonl ← 6 entries
5 targeted skills outperformed 10 generic ones. Every mutation is git-tagged (evo-1, evo-2, …) for full reproducibility.
Quick Start
1. Install
bash# PyPI (recommended) pip install a-evolve # core pip install a-evolve[anthropic] # Claude support pip install a-evolve[mcp] # MCP-Atlas benchmark pip install a-evolve[swe] # SWE-bench benchmark pip install a-evolve[all] # everything # From source (for development) git clone https://github.com/A-EVO-Lab/a-evolve.git && cd a-evolve pip install -e ".[all,dev]"
2. Evolve — 3 Lines of Code
pythonimport agent_evolve as ae evolver = ae.Evolver( agent="swe-verified", # built-in seed workspace (or path to yours) benchmark="swe-verified", # built-in benchmark adapter ) results = evolver.run(cycles=10) print(f"Final score: {results.final_score:.3f}") print(f"Converged: {results.converged}")
A-Evolve ships with built-in seed workspaces (swe, mcp, terminal, skillbench) and benchmark adapters (swe-verified, mcp-atlas, terminal-bench 2.0, skill-bench). Point agent= at any of them — or at your own workspace directory.
3. Bring Your Own Agent (BYOA)
To make any agent evolvable, implement one method — solve():
pythonfrom agent_evolve.protocol.base_agent import BaseAgent from agent_evolve.types import Task, Trajectory class MyAgent(BaseAgent): def solve(self, task: Task) -> Trajectory: return Trajectory(task_id=task.id, output="result")
Then evolve it:
pythonevolver = ae.Evolver(agent=MyAgent("./my_workspace"), benchmark="mcp-atlas") results = evolver.run(cycles=10)
Your agent's evolvable state (prompts, skills, memory) lives as a standard directory — the Agent Workspace. A-Evolve mutates these files; your agent reloads. See Architecture & Design for the full picture.
For benchmark-specific walkthroughs, see SWE-bench Demo Guide, MCP-Atlas Demo Guide, and SkillBench Setup Guide.
Architecture & Design
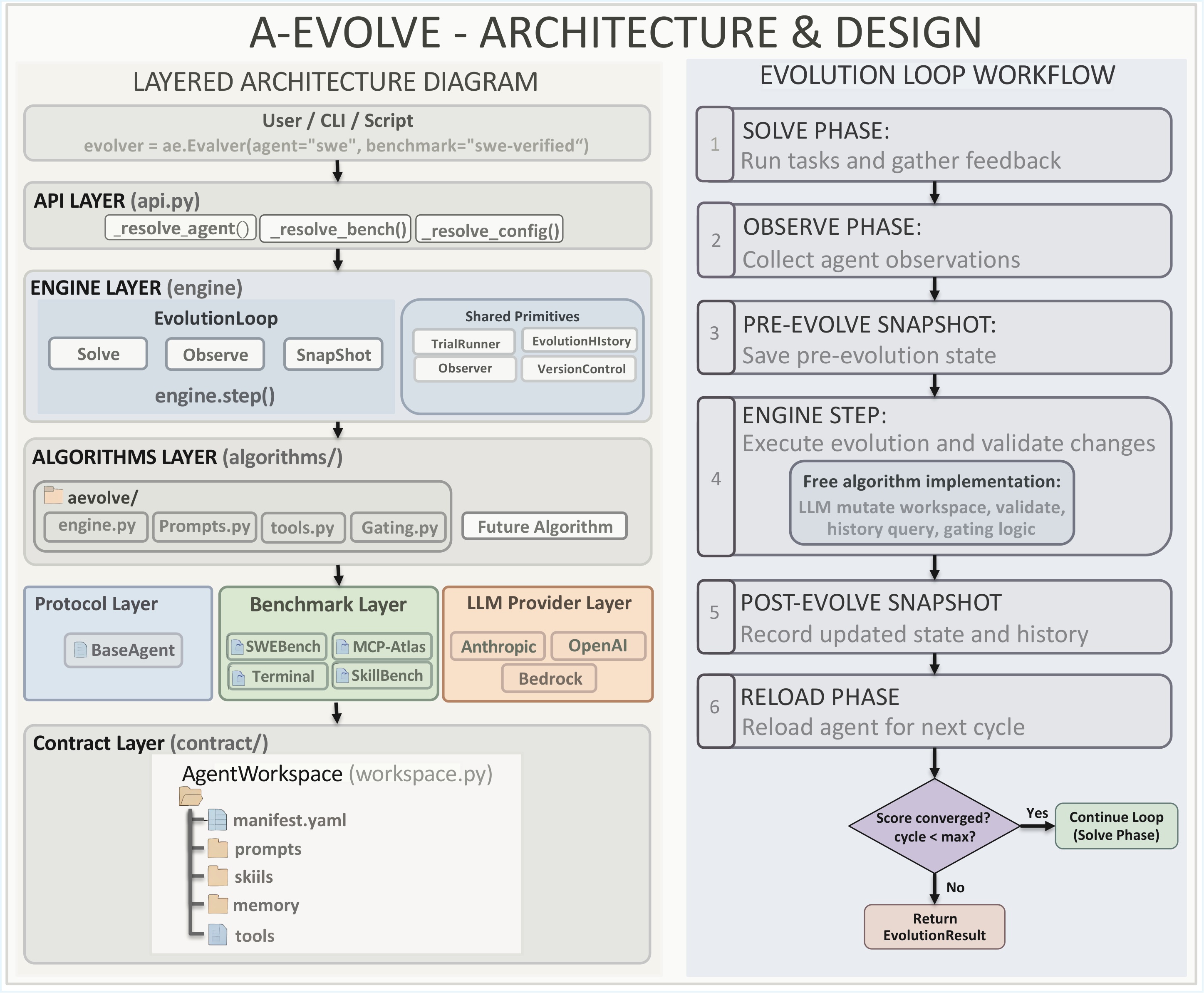
The Agent Workspace: A File System Contract
A-Evolve's core insight: all evolvable agent state lives on the file system as a standard directory structure. This lets the evolution engine mutate any agent via LLM-driven file operations — without knowing the agent's internals.
my_agent/
├── manifest.yaml # identity, entrypoint, evolvable layers
├── prompts/system.md # system prompt
├── skills/ # SKILL.md files (dynamic skill library)
├── tools/ # tool configurations
└── memory/ # episodic + semantic memory (JSONL)
The evolution engine reads these files, analyzes performance logs, and writes mutations back. The agent reloads. That's the entire contract.
The Evolution Loop
Every cycle follows five phases:
┌─────────┐ ┌─────────┐ ┌─────────┐ ┌──────┐ ┌────────┐
│ Solve │───▶│ Observe │───▶│ Evolve │───▶│ Gate │───▶│ Reload │
└─────────┘ └─────────┘ └─────────┘ └──────┘ └────────┘
- Solve — Agent processes a batch of tasks (black-box execution).
- Observe — Collect trajectories + benchmark feedback into structured logs.
- Evolve — Evolution engine analyzes observations and mutates workspace files (prompts, skills, memory).
- Gate — Validate mutations on holdout tasks. Regressed mutations are rolled back via git.
- Reload — Agent reloads from the (possibly rolled-back) workspace.
The loop converges when EGL (Evolutionary Generality Loss) stabilizes or max_cycles is reached. Every accepted mutation is git-tagged (evo-1, evo-2, …), providing a full audit trail.
Built-in Adapters
A-Evolve ships with ready-to-use benchmark adapters and seed workspaces:
| Adapter | Domain | Seed Workspace | Best Result |
|---|---|---|---|
swe-verified | Real-world GitHub issues (Python repos) | seed_workspaces/swe/ | 76.8% (~#5) |
mcp-atlas | Tool-calling via MCP (16+ servers) | seed_workspaces/mcp/ | 79.4% (🥇 #1) |
terminal-bench | Terminal/CLI ops in Docker | seed_workspaces/terminal/ | 76.5% (~#7) |
skill-bench | Agentic skill discovery | seed_workspaces/skillbench/ | 34.9% (~#2) |
cl-bench | Continual-learning rubric evaluation | — | 38.0% |
Pluggability: Bring Your Own Everything
A-Evolve is a framework, not a standalone agent. Every axis is pluggable:
| Axis | Interface | You Provide | Built-in Examples |
|---|---|---|---|
| Agent (BYOA) | BaseAgent.solve() | Any agent architecture — ReAct, Plan-and-Solve, custom | SweAgent, McpAgent |
| Benchmark (BYOE) | BenchmarkAdapter.get_tasks() / .evaluate() | Any domain with task + evaluation signal | SWE-bench, MCP-Atlas, Terminal-Bench 2.0, SkillsBench, CL-bench |
| Algorithm (BYO-Algo) | EvolutionEngine.step() | Any evolution strategy | AEvolveEngine (LLM-driven mutation) |
| LLM Provider | LLMProvider.complete() | Any model API | Anthropic, OpenAI, AWS Bedrock |
Built-in Evolution Algorithms
A-Evolve ships with 4 reference evolution algorithms, each targeting different domains and strategies:
| Algorithm | Strategy | Best For | Docs |
|---|---|---|---|
adaptive_evolve | Per-claim feedback analysis + meta-learning | MCP-Atlas (🥇 #1, 79.4%) | Guide |
adaptive_skill | LLM-driven workspace mutation with bash tool access | Terminal-Bench 2.0 (~#7, 76.5%) | Guide |
skillforge | LLM-driven workspace mutation with EGL gating | SkillsBench (#2, 34.9%) | Guide |
guided_synth | Memory-first evolution + LLM-guided intervention synthesis | General-purpose, SWE-bench (~#5, 76.8%) | Guide |
Plugging in a custom evolution algorithm
Each algorithm lives in its own directory under algorithms/. Implement a single method:
pythonfrom agent_evolve.engine.base import EvolutionEngine from agent_evolve.types import StepResult class MyEvolutionEngine(EvolutionEngine): def step(self, workspace, observations, history, trial) -> StepResult: # Analyze observations, mutate workspace files, optionally run trial tasks ... return StepResult(accepted=True, score=new_score)
Then pass it to the Evolver:
pythonevolver = ae.Evolver( agent="swe-verified", benchmark="swe-verified", engine=MyEvolutionEngine(config), )
The engine has full access to shared primitives — TrialRunner (on-demand validation), EvolutionHistory (observation + version queries), and VersionControl (git-based rollback) — but is never forced to use them. Minimal contract, maximum freedom.
Community & Contributing
A-Evolve is built for the research community. We welcome contributions across every axis of the framework.
For Algorithm Researchers
If you work in LLM self-optimization, reinforcement learning, or agent architectures — implement the EvolutionEngine interface and your algorithm instantly gains access to:
- Diverse environments (SWE-bench, MCP-Atlas, Terminal-Bench 2.0, SkillsBench, and more).
- Standardized agent workspace representations.
- Rigorous evaluation, gating, and logging infrastructure.
Drop your algorithm into agent_evolve/algorithms/your_algo/ and open a PR.
For Benchmark Authors
Implement BenchmarkAdapter to plug any new evaluation domain into A-Evolve. The interface is two methods: get_tasks() and evaluate().
Get Involved
- ⭐ Star this repo to support our research — we are evolving fast.
- 🐛 Open an issue to report bugs or request features.
- 🔀 Submit a PR — new evolution algorithms, benchmark adapters, agent implementations, and documentation improvements are all welcome.
- 💬 Join our Discord to discuss research directions, share results, and collaborate.
Citation
If you use A-Evolve in your research, please cite our position paper:
bibtex@article{lin2026position, title={Position: Agentic Evolution is the Path to Evolving LLMs}, author={Lin, Minhua and Lu, Hanqing and Shi, Zhan and He, Bing and Mao, Rui and Zhang, Zhiwei and Wu, Zongyu and Tang, Xianfeng and Liu, Hui and Dai, Zhenwei and others}, journal={arXiv preprint arXiv:2602.00359}, year={2026} }
License
Contributors
Showing top 7 contributors by commit count.







Related Repositories

Significant-Gravitas/AutoGPT
AutoGPT is the vision of accessible AI for everyone, to use and to build on. Our mission is to provide the tools, so that you can focus on what matters.

langflow-ai/langflow
Langflow is a powerful tool for building and deploying AI-powered agents and workflows.

langchain-ai/langchain
The agent engineering platform.

Shubhamsaboo/awesome-llm-apps
100+ AI Agent & RAG apps you can actually run — clone, customize, ship.

dair-ai/Prompt-Engineering-Guide
🐙 Guides, papers, lessons, notebooks and resources for prompt engineering, context engineering, RAG, and AI Agents.

ruvnet/ruflo
🌊 The leading agent meta-harness for Claude. Deploy intelligent multi-agent swarms, coordinate autonomous workflows, and build conversational AI systems. Features adaptive memory, self-learning swarm intelligence, RAG integration, and native Claude Code / Codex Integration