Train Your Language Model Course
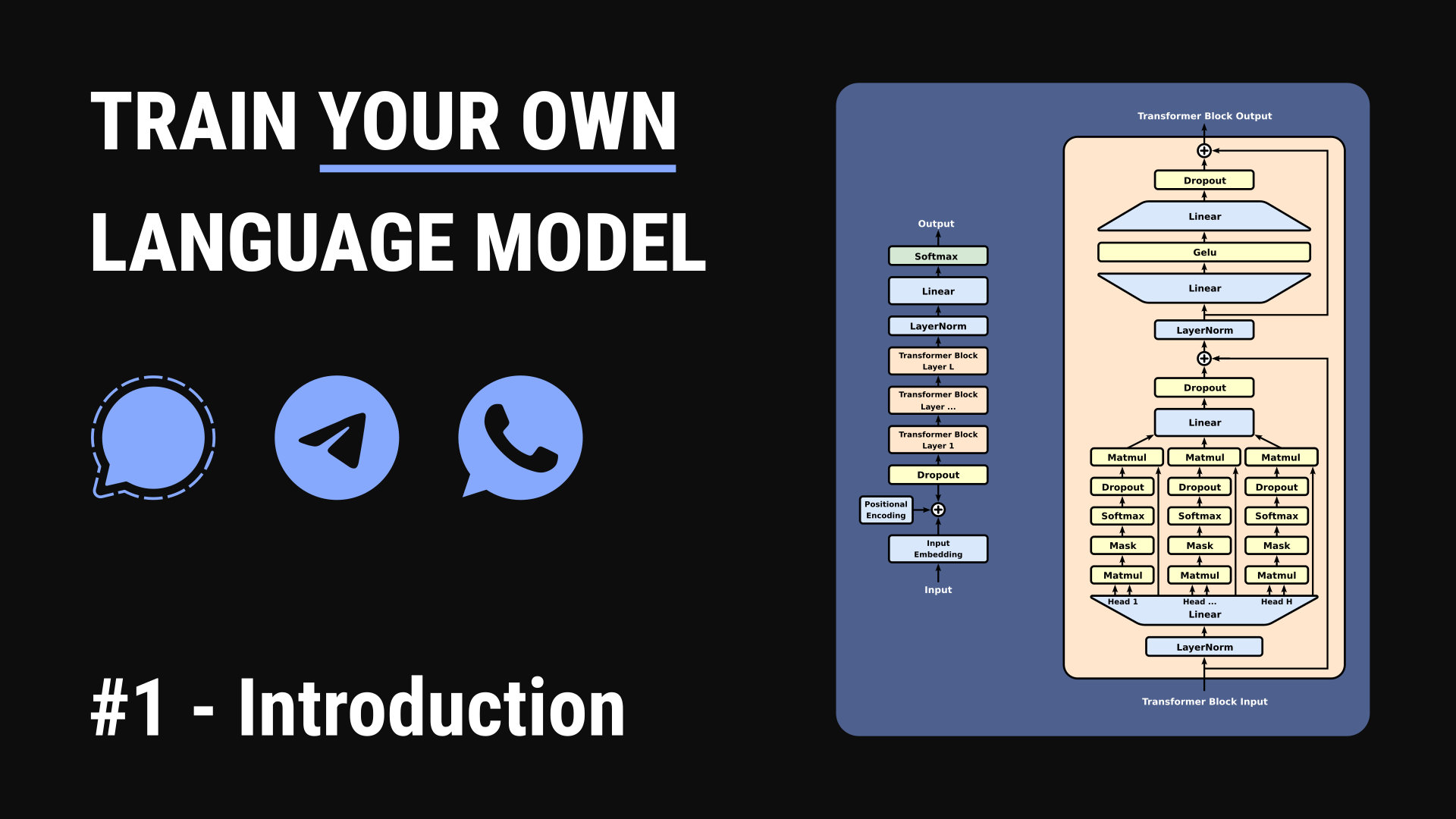
Train a language model to chat like you using your personal conversations from WhatsApp, Telegram, Signal, or other platforms.
We’ve all used Large Language Models (LLMs) and been amazed by what they can do. I wanted to understand how these models are built, so I created this course. The project is written primarily in Jupyter Notebook, first published in 2025. Key topics include: bpe, llm, personae-cloning, tokenization, training-llms.
Train your language model & evolution of the Transformer architecture courses
We’ve all used Large Language Models (LLMs) and been amazed by what they can do. I wanted to understand how these models are built, so I created this course.
I’m from Morocco and speak Moroccan Darija. Most LLMs today understand it a little, but they can't hold proper conversations in Darija. So, as a challenge, I decided to train a language model from scratch using my own WhatsApp conversations in Darija.
I've made a YouTube playlist documenting every step. You can watch it at your own pace. If anything is unclear, feel free to open an issue in this repository. I’ll be happy to help!
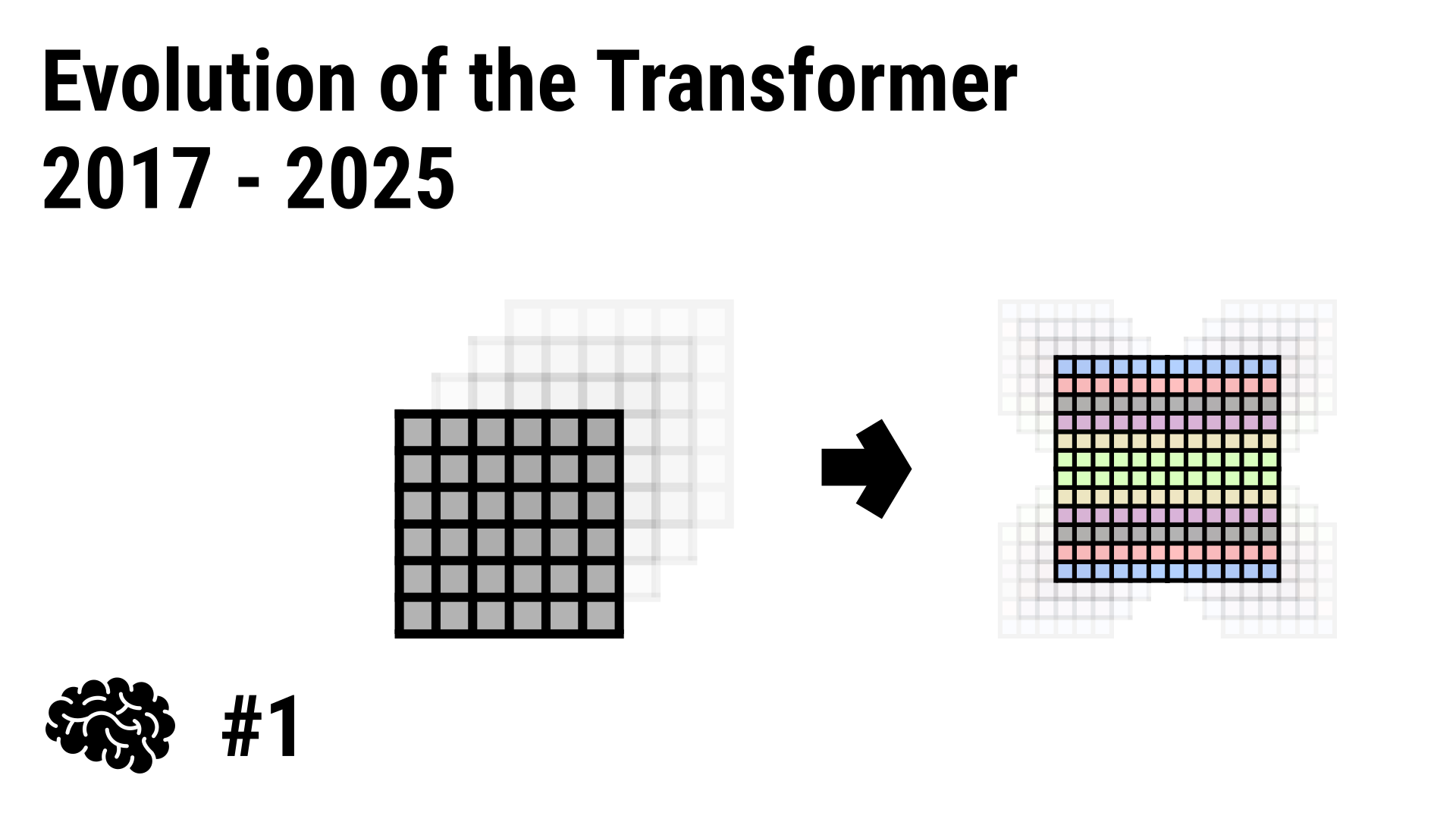
In the first course, I used the Transformer architecture that was introduced in 2017. It is 2025 now, and the Transformer architecture has evolved significantly since then. So, I created a second course to explain the evolution of the Transformer architecture and how to implement some of the recent advancements.
Watch the second course here:
What is in this repository?
notebooks/: Jupyter notebooks for each step in the pipeline.Slides.odp & Slides.pdf: Presentation slides used in the YouTube series.data/: Sample data and templates.transformer/: Scripts for the Transformer and LoRA implementations.minbpe/: A tokenizer from Andrej' Karpathy's repo, since it's not available as a package.RESOURCES.md: List of resources and references.
Setup
To get started, install Python and the required dependencies by running:
bashpip install -r requirements.txt
What you will learn?
Train your language model from scratch course
This course covers:
- Extracting data from WhatsApp.
- Tokenizing text using the BPE algorithm.
- Understanding Transformer models.
- Pre-training the model.
- Creating a fine-tuning dataset.
- Fine-tuning the model (Instruction tuning and LoRA fine-tuning).
Each topic has a video in the YouTube playlist and a Jupyter notebook in the notebooks/ folder.
Evolution of the Transformer architecture course
This course covers:
- Various techniques for encoding positional information
- Different types of attention mechanisms
- Normalization methods and their optimal placement
- Commonly used activation functions
- And much more
Each topic has a video in the YouTube playlist and a Jupyter notebook in the notebooks/ folder.
My experience
Course 1
Like you, I had never trained a language model before. After following the steps in this course, I built my own 42M parameter model called BoDmagh. In Moroccan Darija, BoDmagh can mean someone with a brain. The word Bo + [noun] means something is deep inside you, so BoDmagh can also mean a smart person.
Here are two example conversations I had with the model:
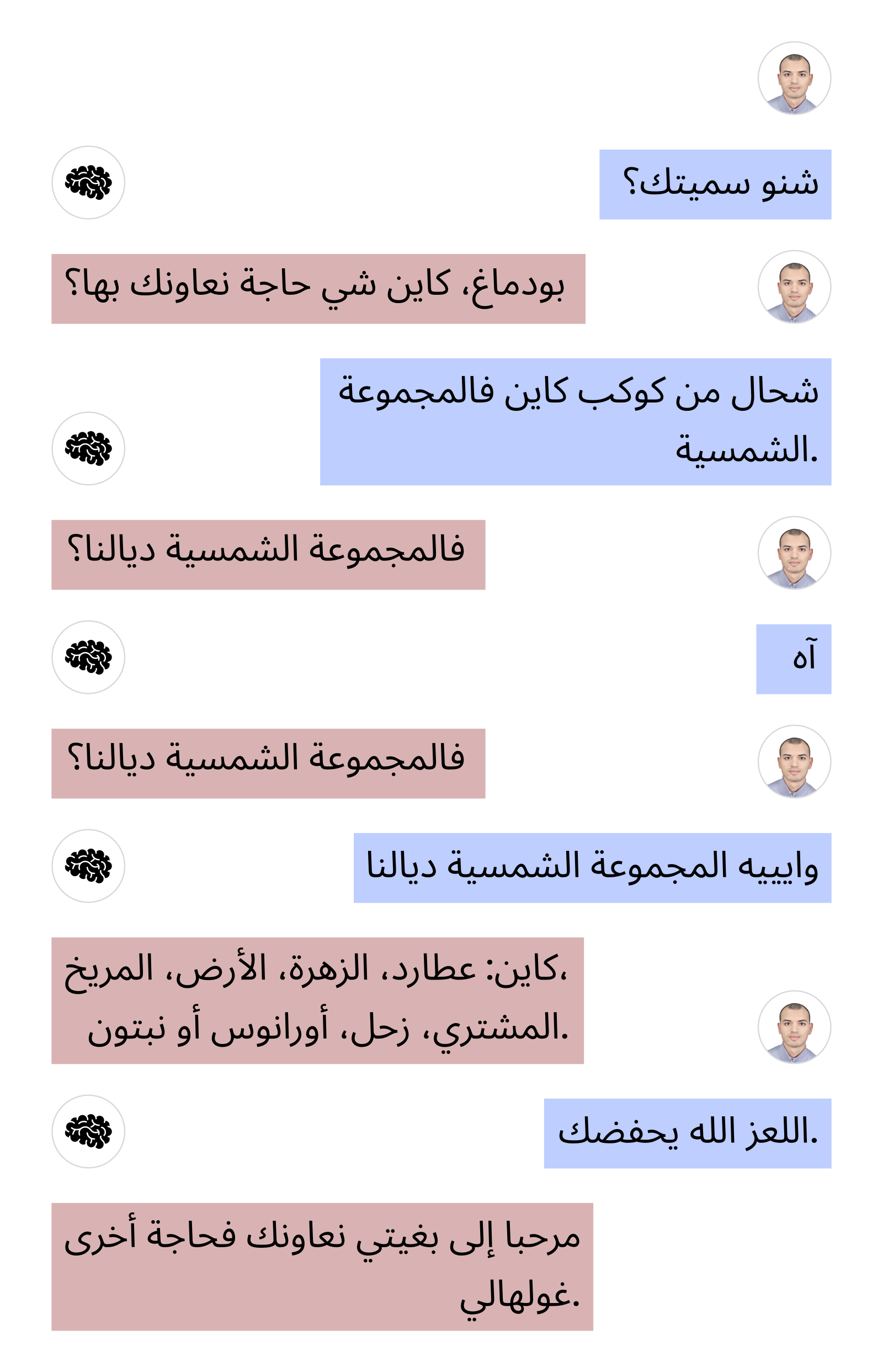
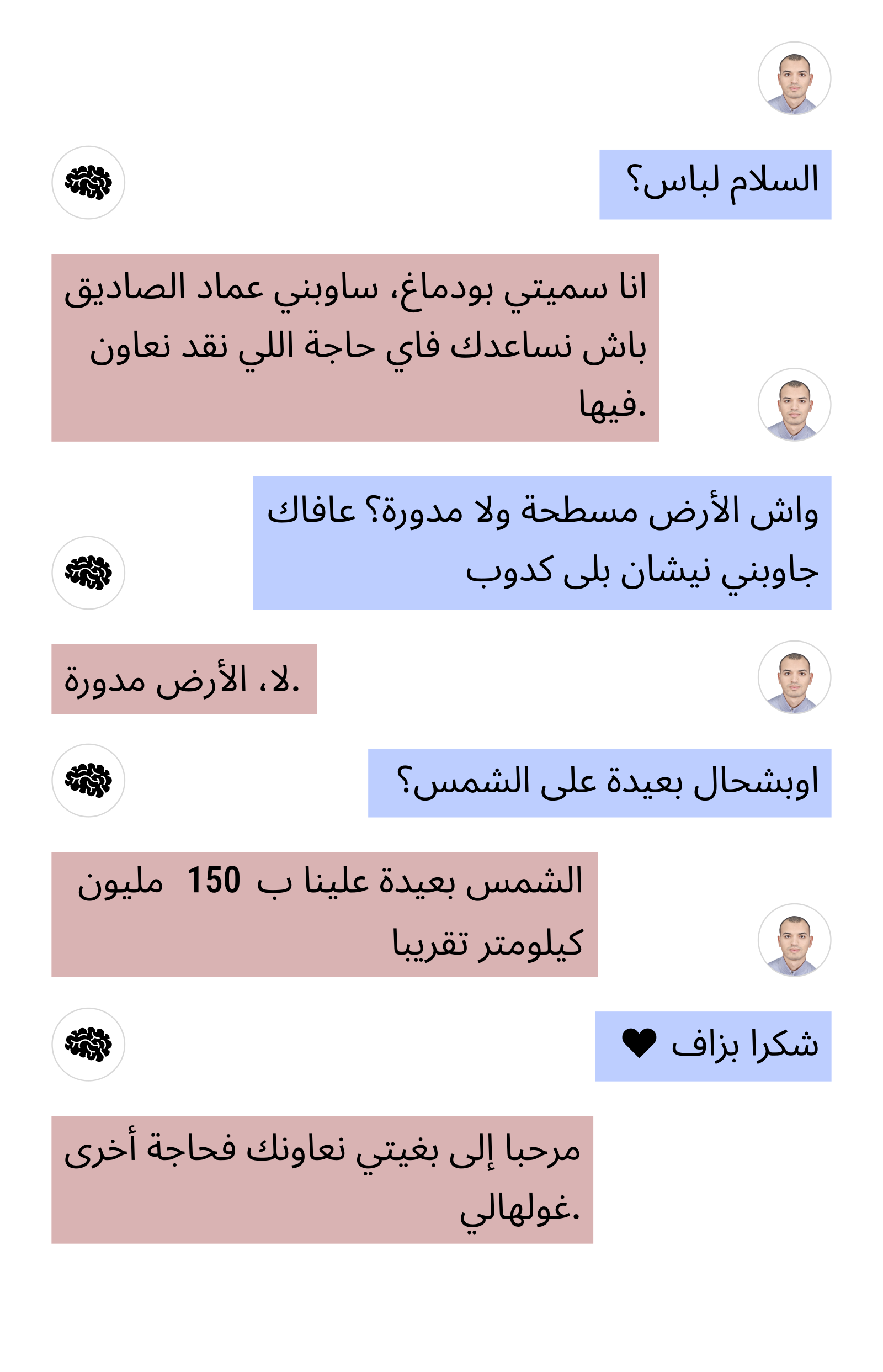
The Supervised Fine-Tuning (SFT) dataset I created really helped improve the model’s ability to hold a conversation.
Course 2
After completing this second course, I compared the performance of the original Transformer model with a modified version that incorporates some of the advancements discussed in the course. I found that these new ideas siginificantly enhanced the Transformer architecture across various aspects such as memory usage, inference speed, better results, etc.
This graph shows the validation loss improving after applying one idea at a time:

Seeing this improvement made me very happy because it confirmed that these advancements are effective and beneficial.
Limitations
The model we trained in the first course doesn’t always give correct answers. If I try to discuss many different topics, it struggles. This is likely because both the model and the SFT dataset are small. Training on more data and using a larger model could improve the results. I might explore this in the future.
Contributions
We welcome contributions! If you find any issues or have suggestions for improvements, please open an issue or submit a pull request.
Need help?
You can reach me through:
- YouTube – Leave a comment on the videos.
- LinkedIn – Connect with me.
- Email – simad3647@gmail.com.
Contributors
Showing top 6 contributors by commit count.






Related Repositories

rsennrich/subword-nmt
Unsupervised Word Segmentation for Neural Machine Translation and Text Generation

VKCOM/YouTokenToMe
Unsupervised text tokenizer focused on computational efficiency

niieani/gpt-tokenizer
The fastest JavaScript BPE Tokenizer Encoder Decoder for OpenAI's GPT models (gpt-5, gpt-o*, gpt-4o, etc.). Port of OpenAI's tiktoken with additional features.

zurawiki/tiktoken-rs
Ready-made tokenizer library for working with GPT and tiktoken

OpenNMT/Tokenizer
Fast and customizable text tokenization library with BPE and SentencePiece support

Kyubyong/nlp_made_easy
Explains nlp building blocks in a simple manner.