Switchboard Corpus
Utilities for Processing the Switchboard Dialogue Act Corpus
Utilities for processing the [Switchboard Dialogue Act Corpus](https://web.stanford.edu/~jurafsky/ws97/) for the purpose of dialogue act (DA) classification. The data is split into the original [training](https://web.stanford.edu/~jurafsky/ws97/ws97-train-convs.list) and [test](https://web.stanford.edu/~jurafsky/ws97/ws97-test-convs.list) sets suggested by the authors (1115 training and 19 test). The remaining 21 dialogues have been used as a validation set. The project is written primarily in Python, distributed under the GNU General Public License v3.0 license, first published in 2018. Key topics include: corpus, corpus-data, corpus-processing, corpus-tools, dialogue.
Processing the Switchboard Dialogue Act Corpus
Utilities for processing the Switchboard Dialogue Act Corpus
for the purpose of dialogue act (DA) classification. The data is split into the original training
and test sets suggested by the authors (1115 training and 19 test).
The remaining 21 dialogues have been used as a validation set.
Scripts
The swda_to_text.py script processes all dialogues into a plain text format. Individual dialogues are saved into directories corresponding
to the set they belong to (train, test, etc). All utterances in a particular set are also saved to a text file.
The utilities.py script contains various helper functions for loading/saving the data.
The process_transcript.py includes functions for processing each dialogue.
The swda_metadata.py generates various metadata from the processed dialogues and saves them as a dictionary to a pickle file.
The words, labels and frequencies are also saved as plain text files in the /metadata directory.
Thanks to Christopher Potts for providing the raw data in .csv format and the swda.py script for processing the .csv data, both of which can be found here
Data Format
Utterance are tagged with the SWBD-DAMSL DA.
By default:
- Utterances are written one per line in the format Speaker | Utterance Text | Dialogue Act Tag.
- Setting the utterance_only_flag == True, will change the default output to only one utterance per line i.e. no speaker or DA tags.
- Utterances marked as Non-verbal ('x' tags) are removed i.e. 'Laughter' or 'Throat_clearing'.
- Utterances marked as Interrupted ('+' tags) and continued later are concatenated to make un-interrupted sentences.
- All disfluency annotations are removed i.e. '#', '<', '>', etc.
Example Utterances
A|What is the nature of your company's business?|qw
B|Well, it's actually, uh,|^h
B|we do oil well services.|sd
Dialogue Acts
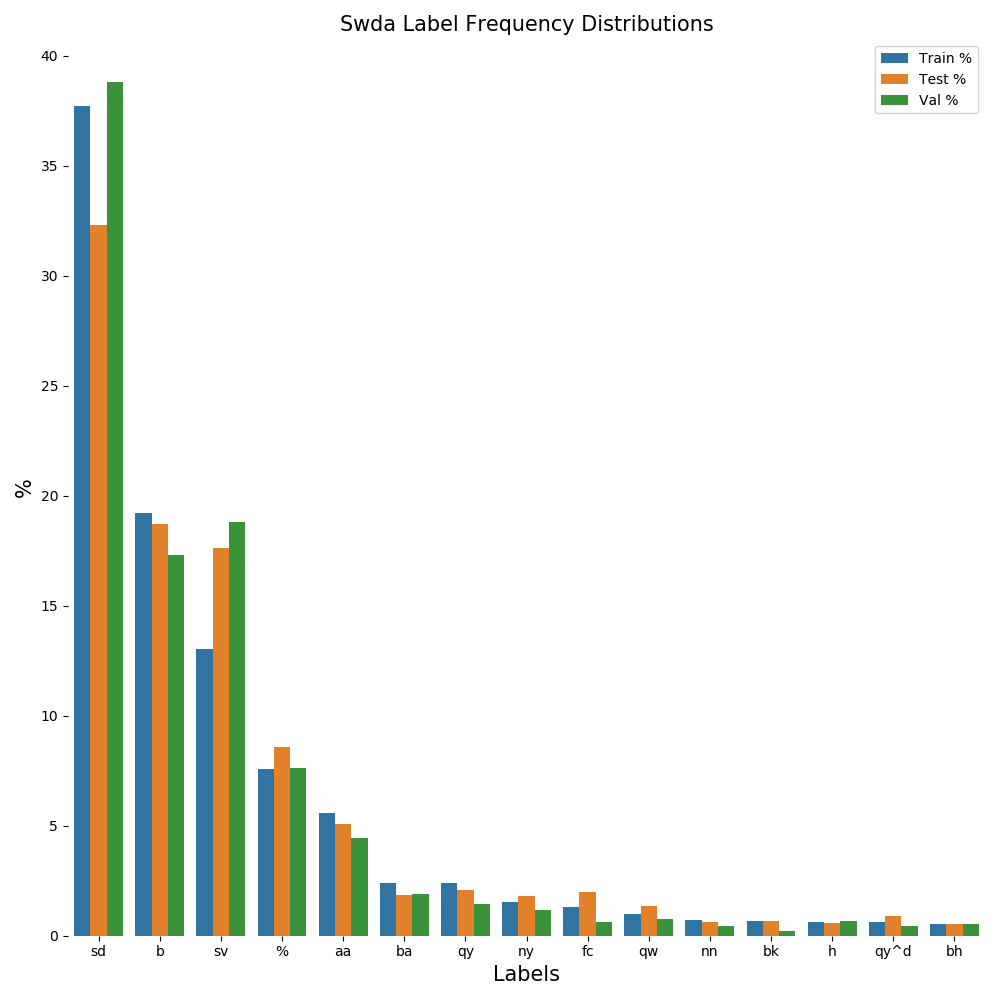
| Dialogue Act | Labels | Count | % | Train Count | Train % | Test Count | Test % | Val Count | Val % |
|---|---|---|---|---|---|---|---|---|---|
| Statement-non-opinion | sd | 75136 | 37.62 | 72549 | 37.71 | 1317 | 32.30 | 1270 | 38.81 |
| Acknowledge (Backchannel) | b | 38281 | 19.17 | 36950 | 19.21 | 764 | 18.73 | 567 | 17.33 |
| Statement-opinion | sv | 26421 | 13.23 | 25087 | 13.04 | 718 | 17.61 | 616 | 18.83 |
| Uninterpretable | % | 15195 | 7.61 | 14597 | 7.59 | 349 | 8.56 | 249 | 7.61 |
| Agree/Accept | aa | 11123 | 5.57 | 10770 | 5.60 | 207 | 5.08 | 146 | 4.46 |
| Appreciation | ba | 4757 | 2.38 | 4619 | 2.40 | 76 | 1.86 | 62 | 1.89 |
| Yes-No-Question | qy | 4725 | 2.37 | 4594 | 2.39 | 84 | 2.06 | 47 | 1.44 |
| Yes Answers | ny | 3030 | 1.52 | 2918 | 1.52 | 73 | 1.79 | 39 | 1.19 |
| Conventional-closing | fc | 2581 | 1.29 | 2480 | 1.29 | 81 | 1.99 | 20 | 0.61 |
| Wh-Question | qw | 1976 | 0.99 | 1896 | 0.99 | 55 | 1.35 | 25 | 0.76 |
| No Answers | nn | 1374 | 0.69 | 1334 | 0.69 | 26 | 0.64 | 14 | 0.43 |
| Response Acknowledgement | bk | 1306 | 0.65 | 1271 | 0.66 | 28 | 0.69 | 7 | 0.21 |
| Hedge | h | 1226 | 0.61 | 1181 | 0.61 | 23 | 0.56 | 22 | 0.67 |
| Declarative Yes-No-Question | qy^d | 1218 | 0.61 | 1167 | 0.61 | 36 | 0.88 | 15 | 0.46 |
| Backchannel in Question Form | bh | 1053 | 0.53 | 1015 | 0.53 | 21 | 0.51 | 17 | 0.52 |
| Quotation | ^q | 983 | 0.49 | 931 | 0.48 | 17 | 0.42 | 35 | 1.07 |
| Summarize/Reformulate | bf | 952 | 0.48 | 905 | 0.47 | 23 | 0.56 | 24 | 0.73 |
| Other | fo_o_fw_"_by_bc | 879 | 0.44 | 857 | 0.45 | 15 | 0.37 | 7 | 0.21 |
| Affirmative Non-yes Answers | na | 847 | 0.42 | 831 | 0.43 | 10 | 0.25 | 6 | 0.18 |
| Action-directive | ad | 745 | 0.37 | 712 | 0.37 | 27 | 0.66 | 6 | 0.18 |
| Collaborative Completion | ^2 | 723 | 0.36 | 690 | 0.36 | 19 | 0.47 | 14 | 0.43 |
| Repeat-phrase | b^m | 687 | 0.34 | 655 | 0.34 | 21 | 0.51 | 11 | 0.34 |
| Open-Question | qo | 656 | 0.33 | 631 | 0.33 | 16 | 0.39 | 9 | 0.28 |
| Rhetorical-Question | qh | 575 | 0.29 | 554 | 0.29 | 12 | 0.29 | 9 | 0.28 |
| Hold Before Answer/Agreement | ^h | 556 | 0.28 | 539 | 0.28 | 7 | 0.17 | 10 | 0.31 |
| Reject | ar | 344 | 0.17 | 337 | 0.18 | 3 | 0.07 | 4 | 0.12 |
| Negative Non-no Answers | ng | 302 | 0.15 | 290 | 0.15 | 6 | 0.15 | 6 | 0.18 |
| Signal-non-understanding | br | 298 | 0.15 | 286 | 0.15 | 9 | 0.22 | 3 | 0.09 |
| Other Answers | no | 284 | 0.14 | 277 | 0.14 | 6 | 0.15 | 1 | 0.03 |
| Conventional-opening | fp | 225 | 0.11 | 220 | 0.11 | 5 | 0.12 | 0 | 0.00 |
| Or-Clause | qrr | 209 | 0.10 | 206 | 0.11 | 2 | 0.05 | 1 | 0.03 |
| Dispreferred Answers | arp_nd | 207 | 0.10 | 204 | 0.11 | 3 | 0.07 | 0 | 0.00 |
| 3rd-party-talk | t3 | 117 | 0.06 | 115 | 0.06 | 0 | 0.00 | 2 | 0.06 |
| Offers, Options Commits | oo_co_cc | 110 | 0.06 | 109 | 0.06 | 0 | 0.00 | 1 | 0.03 |
| Maybe/Accept-part | aap_am | 104 | 0.05 | 97 | 0.05 | 7 | 0.17 | 0 | 0.00 |
| Downplayer | t1 | 103 | 0.05 | 102 | 0.05 | 1 | 0.02 | 0 | 0.00 |
| Self-talk | bd | 103 | 0.05 | 100 | 0.05 | 1 | 0.02 | 2 | 0.06 |
| Tag-Question | ^g | 92 | 0.05 | 92 | 0.05 | 0 | 0.00 | 0 | 0.00 |
| Declarative Wh-Question | qw^d | 80 | 0.04 | 79 | 0.04 | 1 | 0.02 | 0 | 0.00 |
| Apology | fa | 79 | 0.04 | 76 | 0.04 | 2 | 0.05 | 1 | 0.03 |
| Thanking | ft | 78 | 0.04 | 67 | 0.03 | 7 | 0.17 | 4 | 0.12 |
Metadata
- Total number of utterances: 199740
- Max utterance length: 132
- Mean utterance length: 9.62
- Total Number of dialogues: 1155
- Max dialogue length: 457
- Mean dialogue length: 172.94
- Vocabulary size: 22302
- Number of labels: 41
- Number of speakers: 2
Train set
- Number of dialogues: 1115
- Max dialogue length: 457
- Mean dialogue length: 172.55
- Number of utterances: 192390
Test set
- Number of dialogues: 19
- Max dialogue length: 330
- Mean dialogue length: 214.63
- Number of utterances: 4078
Val set
- Number of dialogues: 21
- Max dialogue length: 299
- Mean dialogue length: 155.81
- Number of utterances: 3272
Keys and values for the metadata dictionary
- num_utterances = Total number of utterance in the full corpus.
- max_utterance_len = Number of words in the longest utterance in the corpus.
- mean_utterance_len = Average number of words in utterances.
- num_dialogues = Total number of dialogues in the corpus.
- max_dialogues_len = Number of utterances in the longest dialogue in the corpus.
- mean_dialogues_len = Average number of utterances in dialogues.
- word_freq = Dataframe with Word and Count columns.
- vocabulary = List of all words in vocabulary.
- vocabulary_size = Number of words in the vocabulary.
- label_freq = Dataframe containing all data in the Dialogue Acts table above.
- labels = List of all DA labels.
- num_labels = Number of labels used from the Switchboard data.
- speakers = List of all speakers.
- num_speakers = Number of speakers in the Switchboard data.
Each data set also has:
- <setname>_num_utterances = Number of utterances in the set.
- <setname>_num_dialogues = Number of dialogues in the set.
- <setname>_max_dialogue_len = Length of the longest dialogue in the set.
- <setname>_mean_dialogue_len = Mean length of dialogues in the set.
Related Repositories

brightmart/nlp_chinese_corpus
大规模中文自然语言处理语料 Large Scale Chinese Corpus for NLP

dariusk/corpora
A collection of small corpuses of interesting data for the creation of bots and similar stuff.

CLUEbenchmark/CLUEDatasetSearch
搜索所有中文NLP数据集,附常用英文NLP数据集

wainshine/Chinese-Names-Corpus
中文人名语料库。人名生成器。中文姓名,姓氏,名字,称呼,日本人名,翻译人名,英文人名。可用于中文分词、人名实体识别。
CLUEbenchmark/CLUE
中文语言理解测评基准 Chinese Language Understanding Evaluation Benchmark: datasets, baselines, pre-trained models, corpus and leaderboard

endymecy/awesome-deeplearning-resources
Deep Learning and deep reinforcement learning research papers and some codes