Retinaface
Reimplement RetinaFace use C++ and TensorRT
Reference resources [RetinaFace](https://github.com/deepinsight/insightface/tree/master/RetinaFace) in insightface with python code. The project is written primarily in C++, distributed under the MIT License license, first published in 2019. Key topics include: caffe, int8, mxnet2caffe, retinaface, tensorrt.
RetinaFace C++ Reimplement
source
Reference resources RetinaFace in insightface with python code.
model transformation tool
you need to add some layers yourself, and in caffe there is not upsample,you can replace with deconvolution,and maybe slight accuracy loss.
the origin model reference from mobilenet25,and I have retrain it.
Demo
$ mkdir build
$ cd build/
$ cmake ../
$ make
you need to modify dependency path in CmakeList file.
Speed
test hardware:1080Ti
test1:
| model | speed | input size | preprocess time | inference | postprocess time |
|---|---|---|---|---|---|
| mxnet | 44.8ms | 1280x896 | 19.0ms | 8.0ms | 16.0ms |
| caffe | 46.9ms | 1280x896 | 5.8ms | 24.1ms | 16.0ms |
| tensorrt | 29.3ms | 1280x896 | 6.9ms | 5.4ms | 15.0ms |
test2:
| model | speed | inputsize | preprocess time | inference | postprocess time |
|---|---|---|---|---|---|
| mxnet | 6.4ms | 320x416 | 1.3ms | 0.1ms | 4.2ms |
| caffe | 30.8ms | 320x416 | 1.2ms | 27ms | 2.3ms |
| tensorrt | 4.7ms | 320x416 | 0.7ms | 1.9ms | 1.8ms |
tensorrt batch test:
| batchsize | inputsize | maxbatchsize | preprocess time | inference | postprocess time | all | GPU |
|---|---|---|---|---|---|---|---|
| 1 | 448x448 | 8 | 1.0ms | 2.3ms | 2.6ms | 6.7ms | 35% |
| 2 | 448x448 | 8 | 2.5ms | 3.3ms | 5.2ms | 11.8ms | 33% |
| 4 | 448x448 | 8 | 4.1ms | 4.6ms | 10.0ms | 21.8ms | 28% |
| 8 | 448x448 | 8 | 8.7ms | 7.0ms | 20.3ms | 40.7ms | 23% |
| 16 | 448x448 | 32 | 28.1 | 14.7 | 38.7ms | 92.0ms | - |
| 32 | 448x448 | 32 | 36.2ms | 26.3 | 75.7ms | 163.5ms | - |
note: batch size have some advantage in inference but can't speed up preprocess and postprocess.
optimize post process:
| batchsize | inputsize | maxbatchsize | preprocess time | inference | postprocess time | all | GPU |
|---|---|---|---|---|---|---|---|
| 1 | 448x448 | 8 | 1.0ms | 2.3ms | 0.09ms | 3.5ms | 70% |
| 2 | 448x448 | 8 | 2.2ms | 2.8ms | 0.2ms | 5.3ms | 60% |
| 4 | 448x448 | 8 | 3.7ms | 5.0ms | 0.3ms | 8.4ms | 55% |
| 8 | 448x448 | 8 | 7.5ms | 6.5ms | 0.67ms | 14.9ms | 50% |
| 16 | 448x448 | 32 | 26ms | 13ms | 1.3ms | 41ms | 40% |
| 32 | 448x448 | 32 | 32ms | 22ms | 2.7ms | 56.6ms | 50% |
use nvidia npp library to speed up preprocess:
| batchsize | inputsize | maxbatchsize | preprocess time | inference | postprocess time | all | GPU |
|---|---|---|---|---|---|---|---|
| 1 | 448x448 | 8 | 0.2ms | 2.3ms | 0.1ms | 2.6ms | 91% |
| 2 | 448x448 | 8 | 0.3ms | 3.0ms | 0.2ms | 3.5ms | 85% |
| 4 | 448x448 | 8 | 0.5ms | 4.1ms | 0.32ms | 5.0ms | 82% |
| 8 | 448x448 | 8 | 1.2ms | 6.3ms | 0.77ms | 8.3ms | 79% |
| 16 | 448x448 | 32 | 2.2ms | 14ms | 1.3ms | 16.7ms | 80% |
| 32 | 448x448 | 32 | 5.0ms | 22ms | 2.8ms | 29.3ms | 77% |
INT8 inference
INT8 calibration table can generate by INT8-Calibration-Tool.
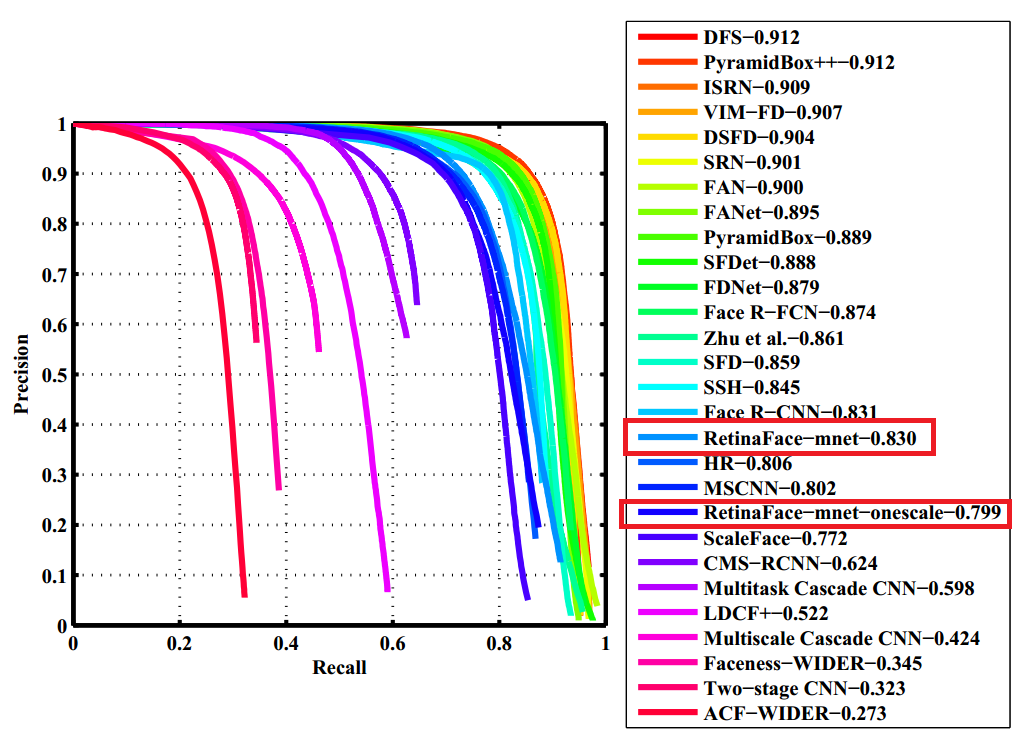
Accuracy
Contributors
Showing top 1 contributor by commit count.

Related Repositories

CMU-Perceptual-Computing-Lab/openpose
OpenPose: Real-time multi-person keypoint detection library for body, face, hands, and foot estimation

donnemartin/data-science-ipython-notebooks
Data science Python notebooks: Deep learning (TensorFlow, Theano, Caffe, Keras), scikit-learn, Kaggle, big data (Spark, Hadoop MapReduce, HDFS), matplotlib, pandas, NumPy, SciPy, Python essentials, AWS, and various command lines.

Tencent/ncnn
ncnn is a high-performance neural network inference framework optimized for the mobile platform

tangyudi/Ai-Learn
人工智能学习路线图,整理近200个实战案例与项目,免费提供配套教材,零基础入门,就业实战!包括:Python,数学,机器学习,数据分析,深度学习,计算机视觉,自然语言处理,PyTorch tensorflow machine-learning,deep-learning data-analysis data-mining mathematics data-science artificial-intelligence python tensorflow tensorflow2 caffe keras pytorch algorithm numpy pandas matplotlib seaborn nlp cv等热门领域

dusty-nv/jetson-inference
Hello AI World guide to deploying deep-learning inference networks and deep vision primitives with TensorRT and NVIDIA Jetson.

likedan/Awesome-CoreML-Models
Largest list of models for Core ML (for iOS 11+)