Vidformer
A drop-in declarative optimization framework for rendering video data visualizations.
A research project for accelerating video/data visualization. See the [preprint on arXiv](https://arxiv.org/abs/2601.17221) for details. The project is written primarily in Rust, distributed under the Apache License 2.0 license, first published in 2024. Key topics include: declarative-video-editing, video, video-query, visualization.
vidformer
![]()
![]()

![]()
![]()

A research project for accelerating video/data visualization.
See the preprint on arXiv for details.
Developed by the OSU Interactive Data Systems Lab.
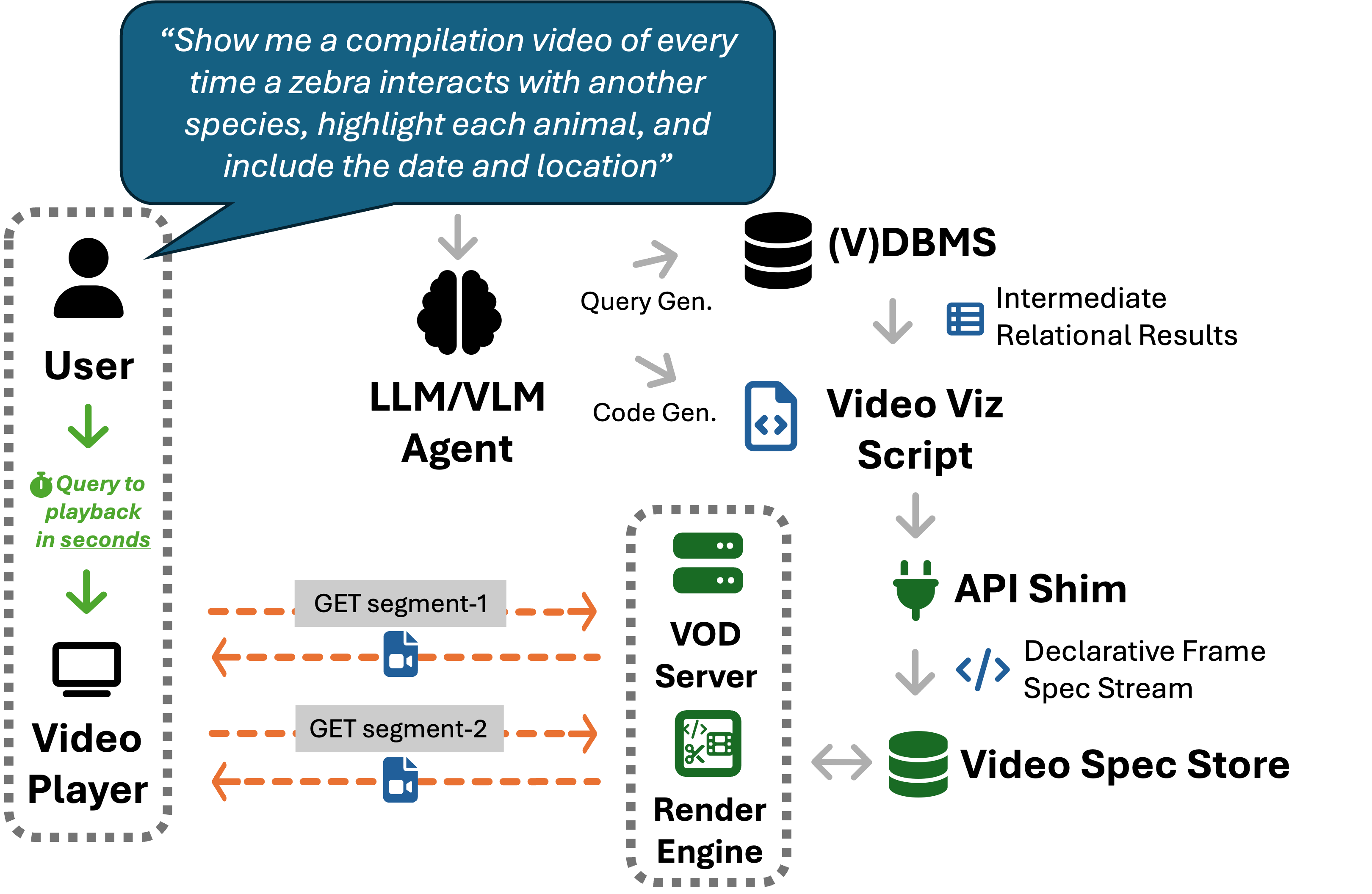
Quick Start
To quickly try out Vidformer you can:

- try the online Vidformer Playground
Or, you can deploy it yourself:
bashgit clone https://github.com/ixlab/vidformer cd vidformer docker build -t igni -f Dockerfile . docker-compose -f vidformer-igni/docker-compose-local.yaml up
You can find details on this in our Getting Started Guide.
Why vidformer
Vidformer efficiently transforms videos, enabling faster annotation, editing, and processing of video data—without having to focus on performance. Just swap import cv2 with import vidformer.cv2 as cv2 to see video outputs instantly.
Vidformer uses a declarative specification format to represent transformations. This enables:
-
Transparent Optimization: Vidformer optimizes the execution of declarative specifications just like a relational database optimizes relational queries.
-
Lazy/Deferred Rendering: Video results can be retrieved on-demand, allowing for practically instantaneous playback of video results.
Vidformer usually renders videos 2-3x faster than cv2, and hundreds of times faster (practically instantly) when serving videos on-demand.
Vidformer builds on open technologies you may already use:
- OpenCV: A
cv2-compatible interface ensures both you (and LLMs) can use existing knowledge and code. - Supervision: Supervision-compatible annotators make visualizing computer vision models trivial.
- FFmpeg: Built on the same libraries, codecs, and formats that run the world.
- Jupyter: View transformed videos instantly right in your notebook.
- HTTP Live Streaming (HLS): Serve transformed videos over a network directly into any media player.
- Apache OpenDAL: Access source videos no matter where they are stored.
Documentation
About the project
Cite:
@misc{winecki2026_vidformer,
title={Vidformer: Drop-in Declarative Optimization for Rendering Video-Native Query Results},
author={Dominik Winecki and Arnab Nandi},
year={2026},
eprint={2601.17221},
archivePrefix={arXiv},
primaryClass={cs.DB},
url={https://arxiv.org/abs/2601.17221},
}
File Layout:
- ./vidformer: The core rendering library (Rust)
- ./vidformer-py: The Python frontend
- ./vidformer-igni: The vidformer server
- ./docs: The project docs
Vidformer components are detailed here.
License: Vidformer is open source under Apache-2.0.
Contributions are welcome.
Acknowledgements: Supported by the Imageomics Institute (NSF Award #2118240) and NSF Award #1910356. Any opinions, findings and conclusions or recommendations expressed in the materials here are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
Contributors
Showing top 3 contributors by commit count.

![dependabot[bot]](https://avatars.githubusercontent.com/in/29110?v=4)
