TVRetrieval
[ECCV 2020] PyTorch code for XML on TVRetrieval dataset - TVR: A Large-Scale Dataset for Video-Subtitle Moment Retrieval
TVRetrieval ===== PyTorch implementation of Cross-modal Moment Localization (XML), an efficient method for video (subtitle) moment localization in corpus level. The project is written primarily in Python, distributed under the MIT License license, first published in 2020. Key topics include: dataset, pytorch, tvc, tvr, video-retrieval.
TVRetrieval
PyTorch implementation of Cross-modal Moment Localization (XML), an efficient method for
video (subtitle) moment localization in corpus level.
TVR: A Large-Scale Dataset for Video-Subtitle Moment Retrieval
Jie Lei, Licheng Yu,
Tamara L. Berg, Mohit Bansal
We introduce TV show Retrieval (TVR), a new multimodal
retrieval dataset. TVR requires systems to understand both videos and
their associated subtitle (dialogue) texts, making it more realistic. The
dataset contains 109K queries collected on 21.8K videos from 6 TV
shows of diverse genres, where each query is associated with a tight
temporal window. The queries are also labeled with query types that
indicate whether each of them is more related to video or subtitle or both,
allowing for in-depth analysis of the dataset and the methods that built
on top of it. Strict qualification and post-annotation verification tests are
applied to ensure the quality of the collected data. Further, we present
several baselines and a novel Cross-modal Moment Localization (XML)
network for multimodal moment retrieval tasks. The proposed XML
model uses a late fusion design with a novel Convolutional Start-End
detector (ConvSE), surpassing baselines by a large margin and with
better efficiency, providing a strong starting point for future work. We
have also collected additional descriptions for each annotated moment in
TVR to form a new multimodal captioning dataset with 262K captions,
named TV show Caption (TVC).
TVR Task

A TVR example in the corpus level moment retrieval task. Ground truth moment is shown in
green box. Colors in the query indicate whether the words are related to video
(blue) or subtitle (magenta) or both (black). To better retrieve relevant moments
from the video corpus, a system needs to comprehend both videos and subtitles
Method - Cross-modal Moment Localization (XML)
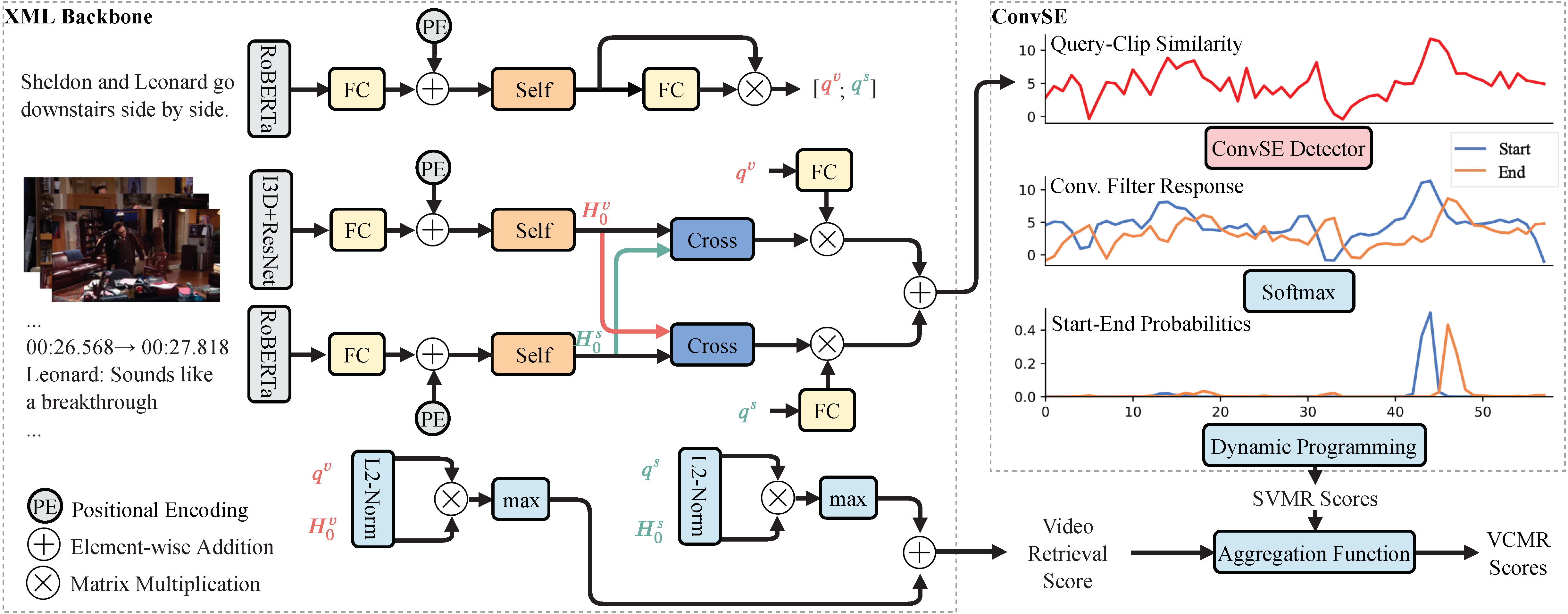
XML is an efficient method for moment retrieval at a large video corpus.
It performs video retrieval in its shallower layers and more fine-grained moment
retrieval in its deeper layers. It uses a late fusion design with a novel
Convolutional Start-End (ConvSE) detector, making the moment predictions efficient and accurate.
The ConvSe module is inspired by edge detectors in image
processing. It learns to detect start (up) and end (down) edges in the 1D query-clip similarity
signals with two trainable 1D convolution filters, and is the core of XML's high accuracy
and efficiency.
Resources
- Data: TVR dataset
- Website (with leaderboard): https://tvr.cs.unc.edu/
- Submission: codalab evaluation server
- Related works: TVC (Video Captioning), TVQA (Localized VideoQA), TVQA+ (Grounded VideoQA)
Getting started
Prerequisites
- Clone this repository
git clone https://github.com/jayleicn/TVRetrieval.git
cd TVRetrieval
- Prepare feature files
Download tvr_feature_release.tar.gz (33GB).
After downloading the feature file, extract it to the data directory:
tar -xf path/to/tvr_feature_release.tar.gz -C data
You should be able to see tvr_feature_release under data directory.
It contains video features (ResNet, I3D) and text features (subtitle and query, from fine-tuned RoBERTa).
Read the code to learn details on how the features are extracted:
video feature extraction, text feature extraction.
- Install dependencies.
- Python 3.7
- PyTorch 1.4.0
- Cuda 10.1
- tensorboard
- tqdm
- h5py
- easydict
To install the dependencies use conda and pip,
you need to have anaconda3 or miniconda3 installed first, then:
conda create --name tvr --file spec-file.txt
conda activate tvr
pip install easydict
- Add project root to
PYTHONPATH
source setup.sh
Note that you need to do this each time you start a new session.
Training and Inference
We give examples on how to perform training and inference for our Cross-modal Moment Localization (XML) model.
- XML training
bash baselines/crossmodal_moment_localization/scripts/train.sh \
tvr CTX_MODE VID_FEAT_TYPE \
--exp_id EXP_ID
CTX_MODE refers to the context (video, sub, tef, etc.) we use.
VID_FEAT_TYPE video feature type (resnet, i3d, resnet_i3d).
EXP_ID is a name string for current run.
Below is an example of training XML with video_sub (video + subtitle),
where video feature is resnet_i3d (ResNet + I3D):
bash baselines/crossmodal_moment_localization/scripts/train.sh \
tvr video_sub resnet_i3d \
--exp_id test_run
This code will load all the data (~60GB) into RAM to speed up training,
use --no_core_driver to disable this behavior. You can also use --debug before actually training the model to
test your configuration.
By default, the model is trained with all the losses, including
video retrieval loss
and moment localization loss .
To train it for only the moment localization, append --lw_neg_q 0 --lw_neg_ctx 0.
To train it for only video retrieval, append --lw_st_ed 0.
Training using the above config will stop at around epoch 60, around 4 hours with a single 2080Ti GPU.
You should get ~2.6 for VCMR R@1, IoU=0.7 on val set.
The resulting model and config will be saved at a dir:
baselines/crossmodal_moment_localization/results/tvr-video_sub-test_run-*.
- XML inference
After training, you can inference using the saved model on val or test_public set:
bash baselines/crossmodal_moment_localization/scripts/inference.sh MODEL_DIR_NAME SPLIT_NAME
MODEL_DIR_NAME is the name of the dir containing the saved model,
e.g., tvr-video_sub-test_run-*.
SPLIT_NAME could be val or test_public.
By default, this code evaluates all the 3 tasks (VCMR, SVMR, VR), you can change this behavior
by appending option, e.g. --tasks VCMR VR where only VCMR and VR are evaluated.
The generated predictions will be saved at the same dir as the model, you can evaluate the predictions
by following the instructions here Evaluation and Submission.
While the default inference code shown above gives you results without non-maximum suppression (NMS),
you can append an additional flag --nms_thd 0.5 to obtain results with NMS. Most likely you will observe
a higher R@5 score, but lower R@{10, 100} scores. For the results reported in the paper,
we do not use NMS.
Other baselines
Except for XML model, we also provide our implementation of CAL,
ExCL and MEE at TVRetrieval/baselines.
Their training, inference and evaluation is similar to XML.
Evaluation and Submission
We only release ground-truth for train and val splits, to get results on test-public split,
please submit your results follow the instructions here:
standalone_eval/README.md
Citations
If you find this code useful for your research, please cite our paper:
@inproceedings{lei2020tvr,
title={TVR: A Large-Scale Dataset for Video-Subtitle Moment Retrieval},
author={Lei, Jie and Yu, Licheng and Berg, Tamara L and Bansal, Mohit},
booktitle={ECCV},
year={2020}
}
Acknowledgement
This research is supported by grants and awards from NSF, DARPA, ARO and Google.
This code borrowed components from the following projects:
transformers,
TVQAplus,
TVQA,
MEE,
we thank the authors for open-sourcing these great projects!
We also thank Victor Escorcia for his kind help on explaining CAL's implementation details.
Contact
jielei [at] cs.unc.edu
Contributors
Showing top 2 contributors by commit count.


Related Repositories

public-apis/public-apis
A collective list of free APIs

HumanSignal/label-studio
Label Studio is a multi-type data labeling and annotation tool with standardized output format

joke2k/faker
Faker is a Python package that generates fake data for you.

lukas-blecher/LaTeX-OCR
pix2tex: Using a ViT to convert images of equations into LaTeX code.

cvat-ai/cvat
Computer Vision Annotation Tool (CVAT) is a leading platform for building high-quality visual datasets for vision AI. It offers open-source, cloud, and enterprise products, as well as labeling services, for image, video, and 3D annotation with AI-assisted labeling, quality assurance, team collaboration, analytics, and developer APIs.

ConardLi/easy-dataset
A powerful tool for creating datasets for LLM fine-tuning 、RAG and Eval