Efficientvit
Efficient vision foundation models for high-resolution generation and perception.
- (🔥 New) [2025/09/05] We will no longer maintain this codebase. All future updates and announcements will be made on [DC-Gen](https://github.com/dc-ai-projects/DC-Gen). - (🔥 New) [2025/01/24] We released DC-AE-SANA-1.1: [doc](https://github.com/mit-han-lab/efficientvit/blob/master/assets/docs/dc_ae_sana_1.1.md). - (🔥 New) [2025/01/23] DC-AE and SANA are accepted by ICLR 2025. - (🔥 New) [2025/01/14] We released **DC-AE+USiT models**: [model](https://huggingface.co/collections/mit-han-lab/dc-... The project is written primarily in Python, distributed under the Apache License 2.0 license, first published in 2023. It has gained significant community traction with 3,321 stars and 250 forks on GitHub. Key topics include: deep-compression-autoencoder, efficient-diffusion-model, efficientvit, high-resolution, imagenet.
Efficient Vision Foundation Models for High-Resolution Generation and Perception
![]()
News
- (🔥 New) [2025/09/05] We will no longer maintain this codebase. All future updates and announcements will be made on DC-Gen.
- (🔥 New) [2025/01/24] We released DC-AE-SANA-1.1: doc.
- (🔥 New) [2025/01/23] DC-AE and SANA are accepted by ICLR 2025.
- (🔥 New) [2025/01/14] We released DC-AE+USiT models: model, training. Using the default training settings and sampling strategy, DC-AE+USiT-2B achieves 1.72 FID on ImageNet 512x512, surpassing the SOTA diffusion model EDM2-XXL and SOTA auto-regressive image generative models (MAGVIT-v2 and MAR-L).
- (🔥 New) [2024/12/24] diffusers supports DC-AE models. All DC-AE models in diffusers safetensors are released. Usage.
- [2024/10/21] DC-AE and EfficientViT block are used in our latest text-to-image diffusion model SANA! Check the project page for more details.
- [2024/10/15] We released Deep Compression Autoencoder (DC-AE): link!
- [2024/07/10] EfficientViT is used as the backbone in Grounding DINO 1.5 Edge for efficient open-set object detection.
- [2024/07/10] EfficientViT-SAM is used in MedficientSAM, the 1st place model in CVPR 2024 Segment Anything In Medical Images On Laptop Challenge.
- [2024/04/06] EfficientViT-SAM is accepted by eLVM@CVPR'24.
- [2024/03/19] Online demo of EfficientViT-SAM is available: https://evitsam.hanlab.ai/.
- [2024/02/07] We released EfficientViT-SAM, the first accelerated SAM model that matches/outperforms SAM-ViT-H's zero-shot performance, delivering the SOTA performance-efficiency trade-off.
- [2023/11/20] EfficientViT is available in the NVIDIA Jetson Generative AI Lab.
- [2023/09/12] EfficientViT is highlighted by MIT home page and MIT News.
- [2023/07/18] EfficientViT is accepted by ICCV 2023.
Content
[ICLR 2025] Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models [paper] [readme] [poster]
Deep Compression Autoencoder (DC-AE) is a new family of high-spatial compression autoencoders with a spatial compression ratio of up to 128 while maintaining reconstruction quality. It accelerates all latent diffusion models regardless of the diffusion model architecture.
Demo

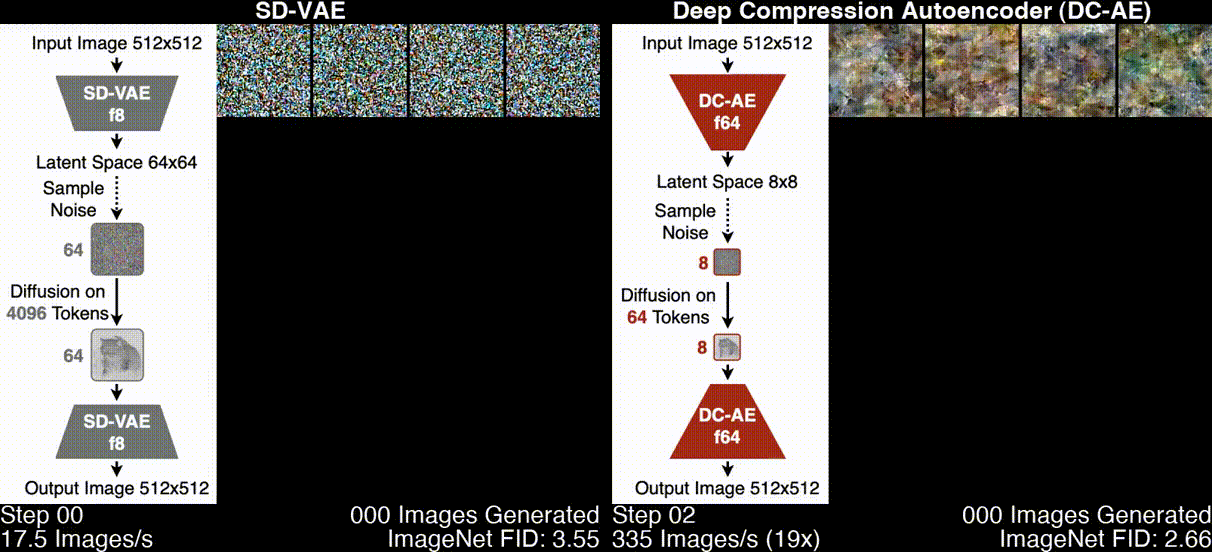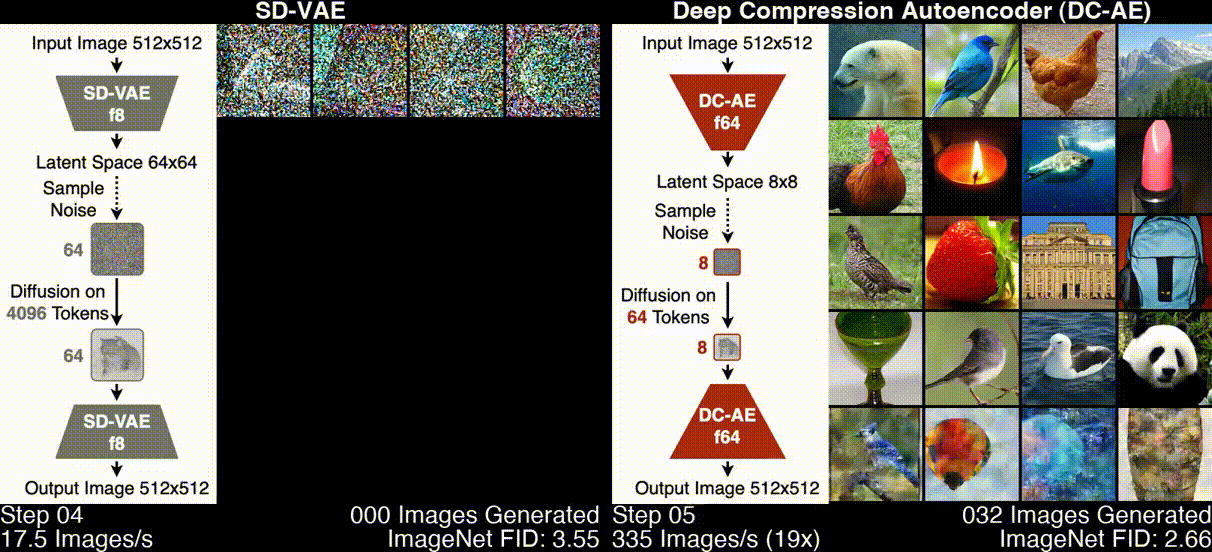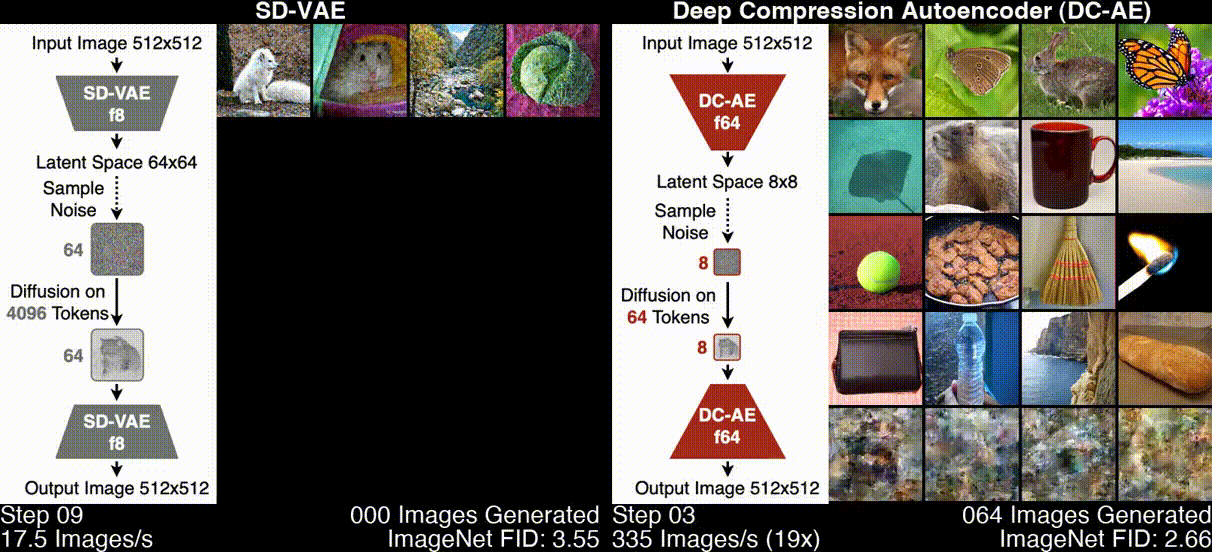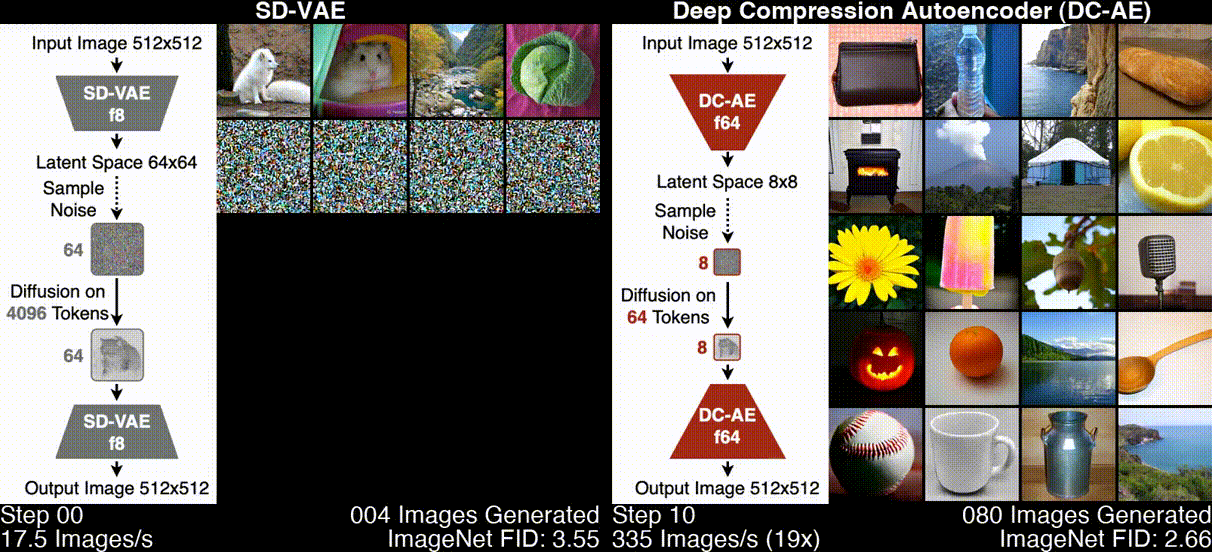
- Usage of Deep Compression Autoencoder
- Usage of DC-AE-Diffusion
- Evaluate Deep Compression Autoencoder
- Demo DC-AE-Diffusion Models
- Evaluate DC-AE-Diffusion Models
- Train DC-AE-Diffusion Models
- Reference
[CVPR 2024 eLVM Workshop] EfficientViT-SAM: Accelerated Segment Anything Model Without Accuracy Loss [paper] [online demo] [readme]
EfficientViT-SAM is a new family of accelerated segment anything models by replacing SAM's heavy image encoder with EfficientViT. It delivers a 48.9x measured TensorRT speedup on A100 GPU over SAM-ViT-H without sacrificing accuracy.
<p align="left"> <img src="https://huggingface.co/mit-han-lab/efficientvit-sam/resolve/main/sam_zero_shot_coco_mAP.png" width="500"> </p>- Pretrained EfficientViT-SAM Models
- Usage of EfficientViT-SAM
- Evaluate EfficientViT-SAM
- Visualize EfficientViT-SAM
- Deploy EfficientViT-SAM
- Train EfficientViT-SAM
- Reference
[ICCV 2023] EfficientViT-Classification [paper] [readme]
Efficient image classification models with EfficientViT backbones.
<p align="left"> <img src="https://huggingface.co/han-cai/efficientvit-cls/resolve/main/efficientvit_cls_results.png" width="600"> </p>- Pretrained EfficientViT Classification Models
- Usage of EfficientViT Classification Models
- Evaluate EfficientViT Classification Models
- Export EfficientViT Classification Models
- Train EfficientViT Classification Models
- Reference
[ICCV 2023] EfficientViT-Segmentation [paper] [readme]
Efficient semantic segmantation models with EfficientViT backbones.

- Pretrained EfficientViT Segmentation Models
- Usage of EfficientViT Segmentation Models
- Evaluate EfficientViT Segmentation Models
- Visualize EfficientViT Segmentation Models
- Export EfficientViT Segmentation Models
- Reference
EfficientViT-GazeSAM [readme]
Gaze-prompted image segmentation models capable of running in real time with TensorRT on an NVIDIA RTX 4070.

Getting Started
bashconda create -n efficientvit python=3.10 conda activate efficientvit pip install -U -r requirements.txt
Third-Party Implementation/Integration
Contact
Reference
If EfficientViT or EfficientViT-SAM or DC-AE is useful or relevant to your research, please kindly recognize our contributions by citing our paper:
bibtex@inproceedings{cai2023efficientvit, title={Efficientvit: Lightweight multi-scale attention for high-resolution dense prediction}, author={Cai, Han and Li, Junyan and Hu, Muyan and Gan, Chuang and Han, Song}, booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision}, pages={17302--17313}, year={2023} }
bibtex@article{zhang2024efficientvit, title={EfficientViT-SAM: Accelerated Segment Anything Model Without Performance Loss}, author={Zhang, Zhuoyang and Cai, Han and Han, Song}, journal={arXiv preprint arXiv:2402.05008}, year={2024} }
bibtex@article{chen2024deep, title={Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models}, author={Chen, Junyu and Cai, Han and Chen, Junsong and Xie, Enze and Yang, Shang and Tang, Haotian and Li, Muyang and Lu, Yao and Han, Song}, journal={arXiv preprint arXiv:2410.10733}, year={2024} }
Contributors
Showing top 12 contributors by commit count.












