Proxylessnas
[ICLR 2019] ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware
- ProxylessNAS is integrated into [PytorchHub](https://pytorch.org/hub/pytorch_vision_proxylessnas/). - ProxylessNAS is integrated into Microsoft [NNI](https://nni.readthedocs.io/en/v1.6/NAS/Proxylessnas.html). - ProxylessNAS is integrated into Amazon [AutoGluon](https://auto.gluon.ai/0.3.0/tutorials/nas/enas_proxylessnas.html). - First place in the Visual Wake Words Challenge, TF-lite track, @CVPR 2019 - Third place in the Low Power Image Recognition Challenge (LPIRC), classification track, @CV... The project is written primarily in C++, distributed under the MIT License license, first published in 2018. It has gained significant community traction with 1,447 stars and 284 forks on GitHub. Key topics include: acceleration, automl, efficient-model, hardware-aware, on-device-ai.
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware [arXiv] [Poster]
bash@inproceedings{ cai2018proxylessnas, title={Proxyless{NAS}: Direct Neural Architecture Search on Target Task and Hardware}, author={Han Cai and Ligeng Zhu and Song Han}, booktitle={International Conference on Learning Representations}, year={2019}, url={https://arxiv.org/pdf/1812.00332.pdf}, }
News
- ProxylessNAS is integrated into PytorchHub.
- ProxylessNAS is integrated into Microsoft NNI.
- ProxylessNAS is integrated into Amazon AutoGluon.
- First place in the Visual Wake Words Challenge, TF-lite track, @CVPR 2019
- Third place in the Low Power Image Recognition Challenge (LPIRC), classification track, @CVPR 2019
Performance
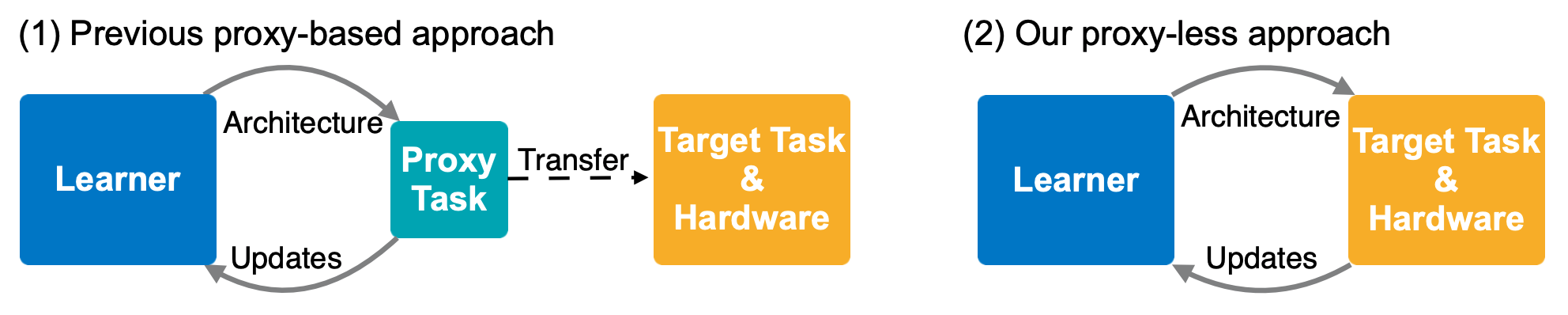
Without any proxy, directly and efficiently search neural network architectures on your target task and hardware!
Now, proxylessnas is on PyTorch Hub. You can load it with only two lines!
pythontarget_platform = "proxyless_cpu" # proxyless_gpu, proxyless_mobile, proxyless_mobile14 are also avaliable. model = torch.hub.load('mit-han-lab/ProxylessNAS', target_platform, pretrained=True)
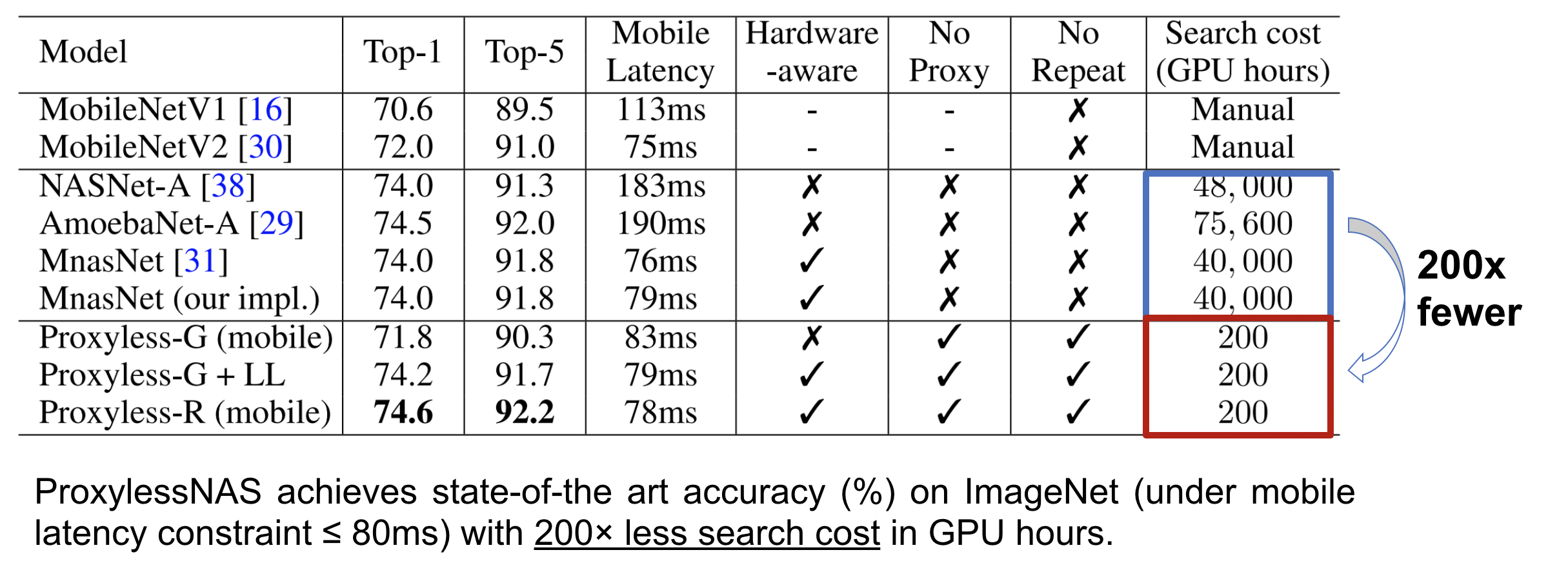
| Model | Top-1 | Top-5 | Latency |
|---|---|---|---|
| MobilenetV2 | 72.0 | 91.0 | 6.1ms |
| ShufflenetV2(1.5) | 72.6 | - | 7.3ms |
| ResNet-34 | 73.3 | 91.4 | 8.0ms |
| MNasNet(our impl) | 74.0 | 91.8 | 6.1ms |
| ProxylessNAS (GPU) | 75.1 | 92.5 | 5.1ms |
Specialization
People used to deploy one model to all platforms, but this is not good. To fully exploit the efficiency, we should specialize architectures for each platform.

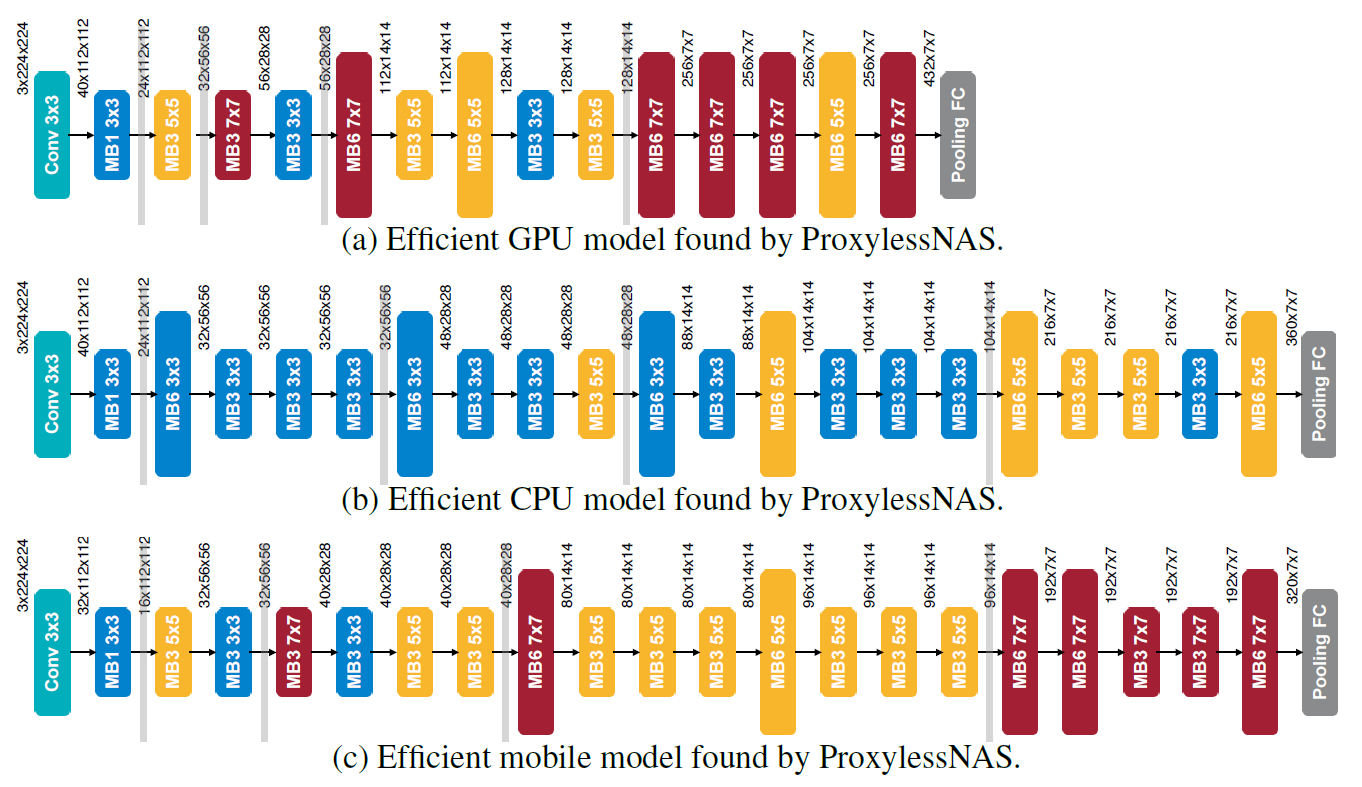
We provide a visualization of search process. Please refer to our paper for more results.
How to use / evaluate
-
Use
python# pytorch from proxyless_nas import proxyless_cpu, proxyless_gpu, proxyless_mobile, proxyless_mobile_14, proxyless_cifar net = proxyless_cpu(pretrained=True) # Yes, we provide pre-trained models!python# tensorflow from proxyless_nas_tensorflow import proxyless_cpu, proxyless_gpu, proxyless_mobile, proxyless_mobile_14 tf_net = proxyless_cpu(pretrained=True)If the above scripts failed to download, you download it manually from Google Drive and put them under
$HOME/.torch/proxyless_nas/. -
Evaluate
python eval.py --path 'Your path to imagent' --arch proxyless_cpu # pytorch ImageNetpython eval.py -d cifar10 # pytorch cifar10python eval_tf.py --path 'Your path to imagent' --arch proxyless_cpu # tensorflow
File structure
- search: code for neural architecture search.
- training: code for training searched models.
- proxyless_nas_tensorflow: pretrained models for tensorflow.
- proxyless_nas: pretrained models for PyTorch.
Projects with ProxylessNAS:
- ProxylessGaze: Real-time Gaze Estimation with ProxylessNAS
Related work on automated model compression and acceleration:
Once for All: Train One Network and Specialize it for Efficient Deployment (ICLR'20, code)
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware (ICLR’19)
AMC: AutoML for Model Compression and Acceleration on Mobile Devices (ECCV’18)
HAQ: Hardware-Aware Automated Quantization (CVPR’19, oral)
Defenstive Quantization: When Efficiency Meets Robustness (ICLR'19)
Contributors
Showing top 5 contributors by commit count.



![dependabot[bot]](https://avatars.githubusercontent.com/in/29110?v=4)

Related Repositories

linearmouse/linearmouse
The mouse and trackpad utility for Mac.

gkjohnson/three-mesh-bvh
A BVH implementation to speed up raycasting and enable spatial queries against three.js meshes.

mit-han-lab/temporal-shift-module
[ICCV 2019] TSM: Temporal Shift Module for Efficient Video Understanding
mit-han-lab/once-for-all
[ICLR 2020] Once for All: Train One Network and Specialize it for Efficient Deployment

PKU-YuanGroup/Helios
Helios: Real Real-Time Long Video Generation Model
mit-han-lab/torchsparse
[MICRO'23, MLSys'22] TorchSparse: Efficient Training and Inference Framework for Sparse Convolution on GPUs.