Discover books
发现图书:豆瓣图书关系图
从豆瓣某一指定图书页开始抓取豆瓣推荐书目,图书与图书之间建立 RELATE 关系;之后可以使用 Neo4j Browser() 浏览图书。 The project is written primarily in Python, distributed under the MIT License license, first published in 2017. Key topics include: books, douban, douban-book, douban-crawler, neo4j.
发现图书
从豆瓣某一指定图书页开始抓取豆瓣推荐书目,图书与图书之间建立 RELATE 关系;之后可以使用 Neo4j Browser(http://localhost:7474) 浏览图书。
欢迎 star,欢迎提交 pull requests :hatching_chick:
安装
-
首先安装 neo4j
-
再安装 Python 依赖:
$ pip install requirements.txt -
最后修改
crawler/config.py中的NEO4J_AUTH:NEO4J_AUTH = ('你的 neo4j 用户名,默认一般为 neo4j', '你的 neo4j 密码')
运行
以 'https://book.douban.com/subject/3112503/'(-u) 作为起点开始抓取,最多抓取 100(-C) 本书,开启 8(-t) 个线程:
$ python start_crawler.py -u 'https://book.douban.com/subject/3112503/' -C 100 -t 8
# windows 系统下
$ python start_crawler.py -u https://book.douban.com/subject/3112503/ -C 100 -t 8
打印帮助信息:
$ python start_crawler.py -h
以 'https://book.douban.com/subject/3112503/' 作为起点抓取的 100 本书:
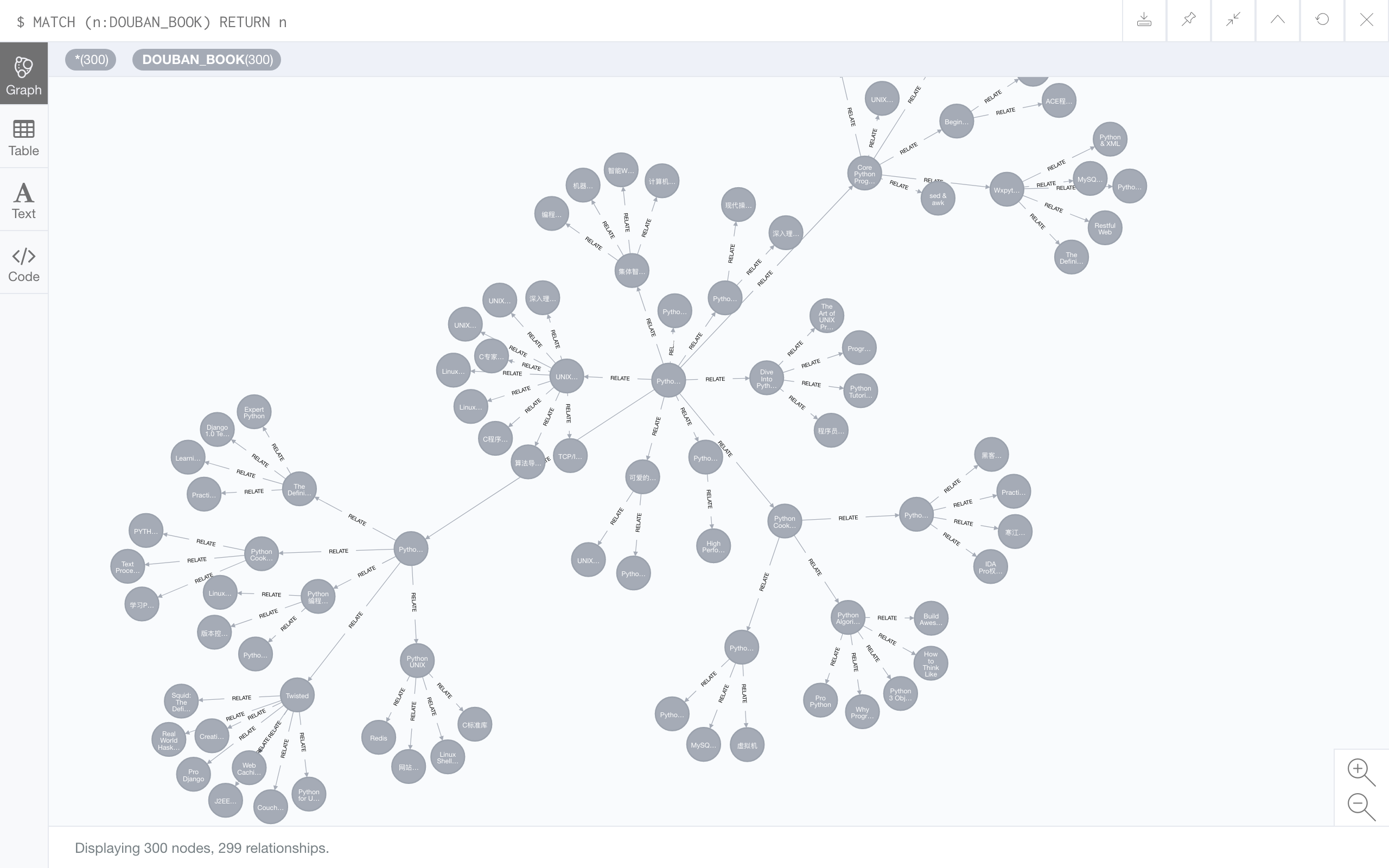
以 'https://book.douban.com/subject/27025715/' 作为起点抓取的 200 本书:
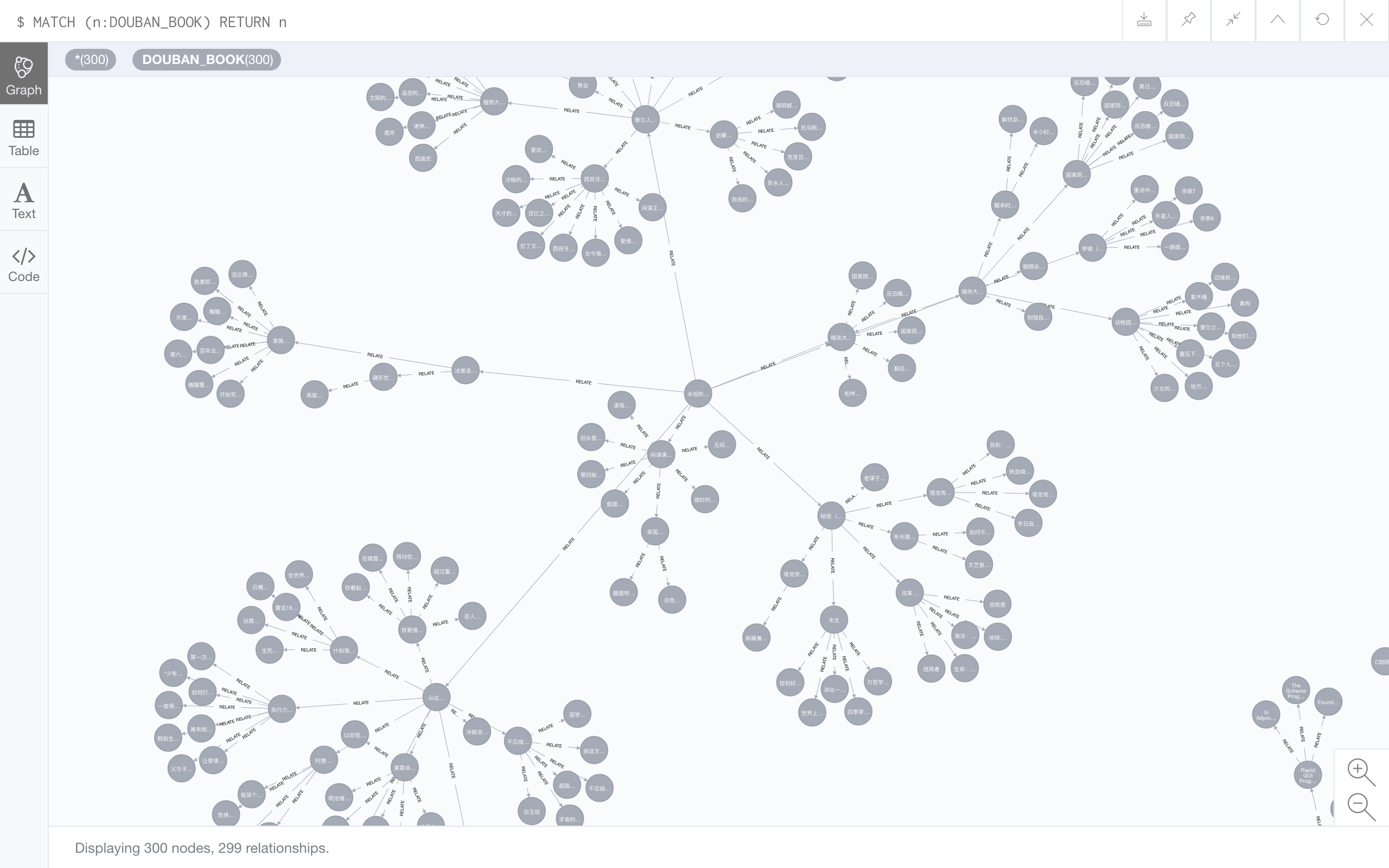
测试
$ pip install -r requirements-dev.txt
$ pytest
已测试通过 python2.7, python3.6
一些 cypher 语句
查看与某一本书有关联的书:
# 替换 book_id 为你想要查看的书
match p=(n:DOUBAN_BOOK {book_id:3112503})-[:RELATE*]-() return p
# 限制返回数量:
match p=(n:DOUBAN_BOOK {book_id:3112503})-[:RELATE*]-() return p limit 30
删除数据库数据:
# 删除与某一本书有关的所有数据(包括node和relation)
match p=(n:DOUBAN_BOOK {book_id:3112503})-[:RELATE*]-() delete p
# 删除数据库中所有抓取的图书
match (n:DOUBAN_BOOK) detach delete n
License
Contributors
Showing top 1 contributor by commit count.

Related Repositories

EbookFoundation/free-programming-books
:books: Freely available programming books

justjavac/free-programming-books-zh_CN
:books: 免费的计算机编程类中文书籍,欢迎投稿

sdmg15/Best-websites-a-programmer-should-visit
:link: Some useful websites for programmers.

FallibleInc/security-guide-for-developers
Security Guide for Developers

dariubs/GoBooks
List of Golang books

ramitsurana/awesome-kubernetes
A curated list for awesome kubernetes sources :ship::tada: