OpenEMMA
OpenEMMA, a permissively licensed open source "reproduction" of Waymo’s EMMA model.
**OpenEMMA** is an open-source implementation of [Waymo's End-to-End Multimodal Model for Autonomous Driving (EMMA)](https://waymo.com/blog/2024/10/introducing-emma/), offering an end-to-end framework for motion planning in autonomous vehicles. **OpenEMMA** leverages the pretrained world knowledge of Vision Language Models (VLMs), such as GPT-4 and LLaVA, to integrate text and front-view camera inputs, enabling precise predictions of future ego waypoints and providing decision rationales. Our ... The project is written primarily in Python, distributed under the Apache License 2.0 license, first published in 2024. Key topics include: algorithms, artificial-intelligence, autonomous-car, autonomous-driving, autonomous-vehicles.
![]()
OpenEMMA: Open-Source Multimodal Model for End-to-End Autonomous Driving
OpenEMMA is an open-source implementation of Waymo's End-to-End Multimodal Model for Autonomous Driving (EMMA), offering an end-to-end framework for motion planning in autonomous vehicles. OpenEMMA leverages the pretrained world knowledge of Vision Language Models (VLMs), such as GPT-4 and LLaVA, to integrate text and front-view camera inputs, enabling precise predictions of future ego waypoints and providing decision rationales. Our goal is to provide accessible tools for researchers and developers to advance autonomous driving research and applications.
<div align="center"> <img src="assets/EMMA-Paper-1__3_.webp" alt="EMMA diagram" width="800"/> <p><em>Figure 1. EMMA: Waymo's End-to-End Multimodal Model for Autonomous Driving.</em></p> </div> <div align="center"> <img src="assets/openemma-pipeline.png" alt="OpenEMMA diagram" width="800"/> <p><em>Figure 2. OpenEMMA: Our Open-Source End-to-End Autonomous Driving Framework based on Pre-trained VLMs.</em></p> </div>News
- [2025/1/12] 🔥OpenEMMA is now available as a PyPI package! You can install it using
pip install openemma. - [2024/12/19] 🔥We released OpenEMMA, an open-source project for end-to-end motion planning in autonomous driving tasks. Explore our paper for more details.
Table of Contents
Demos
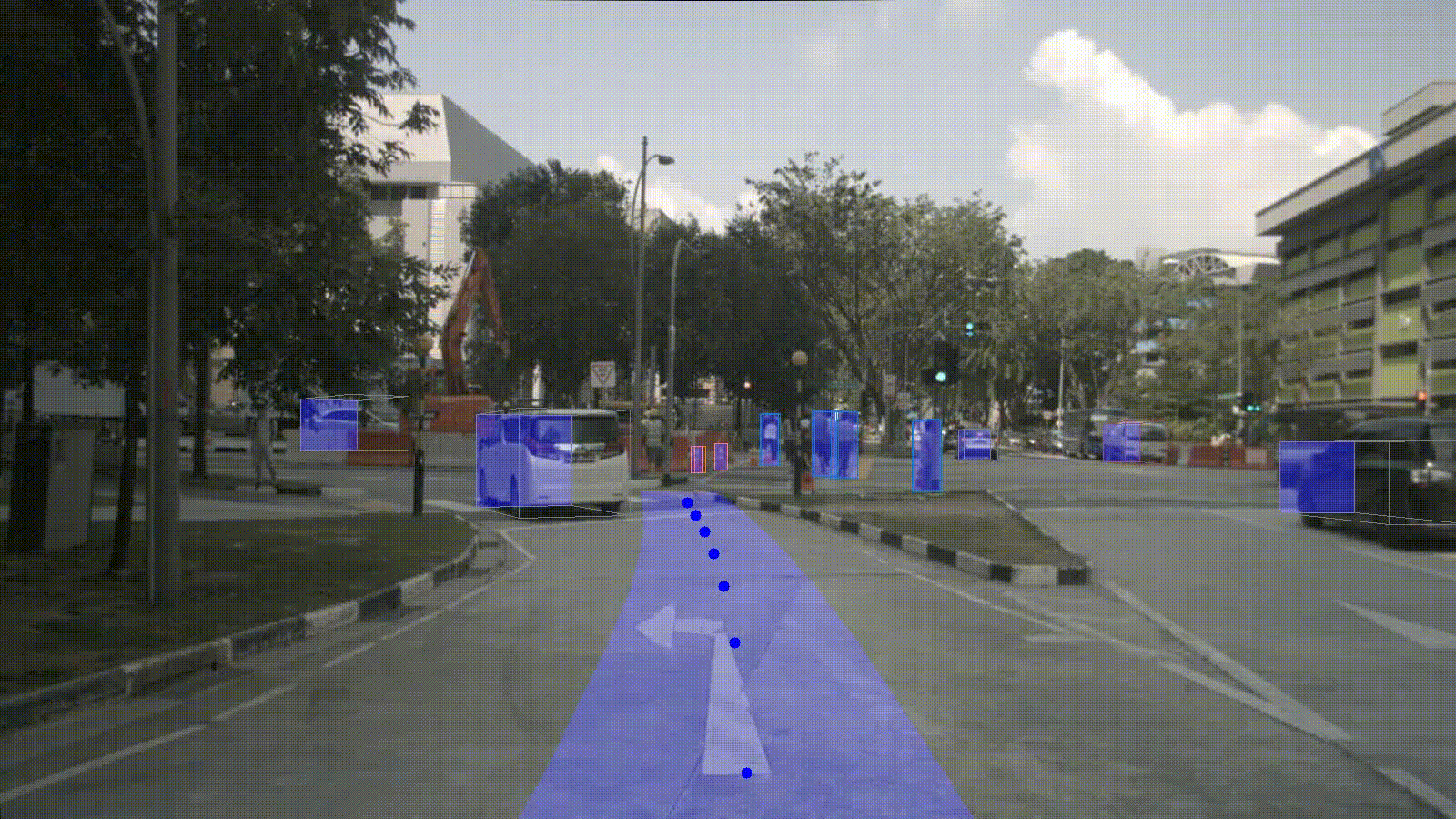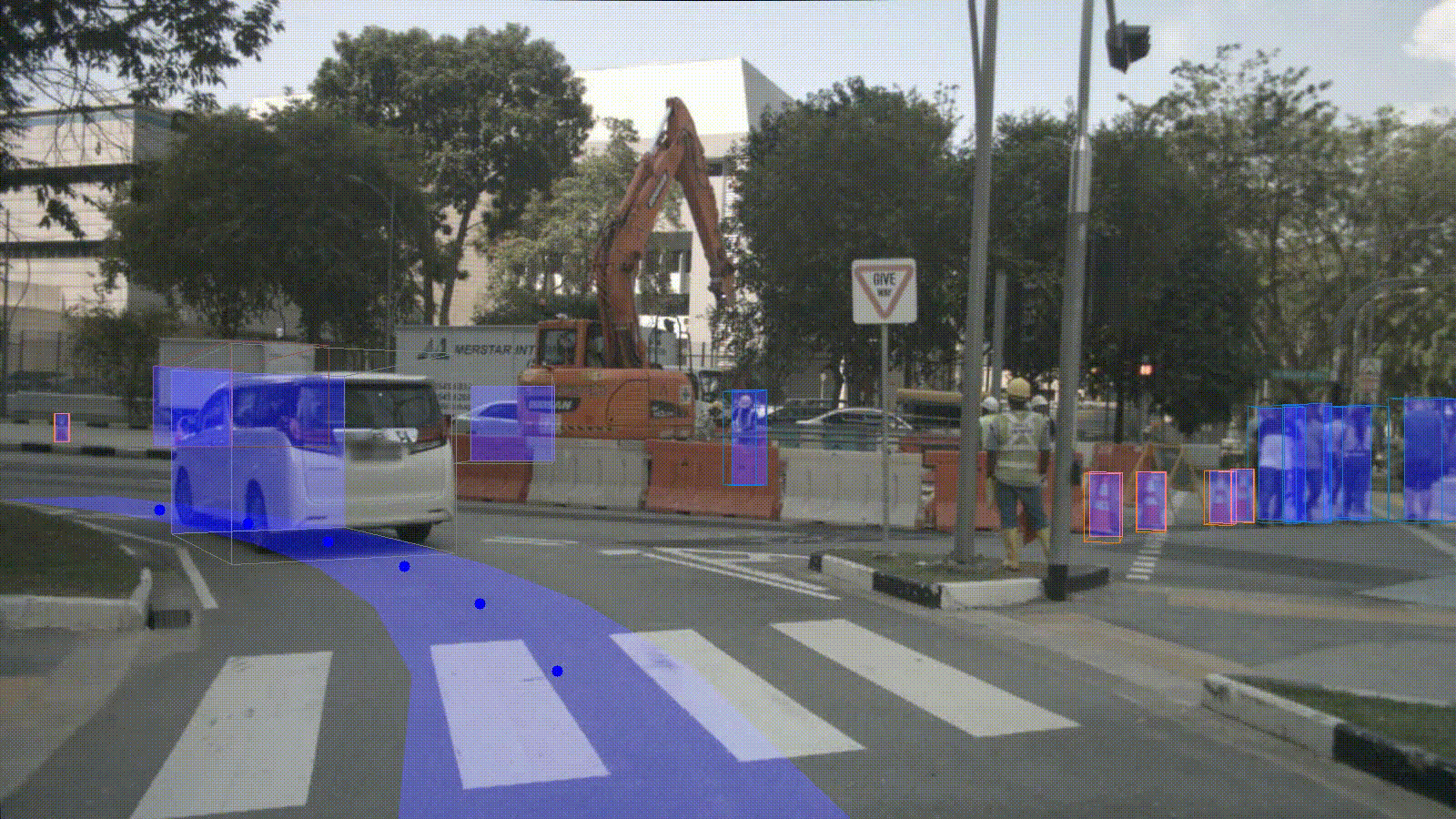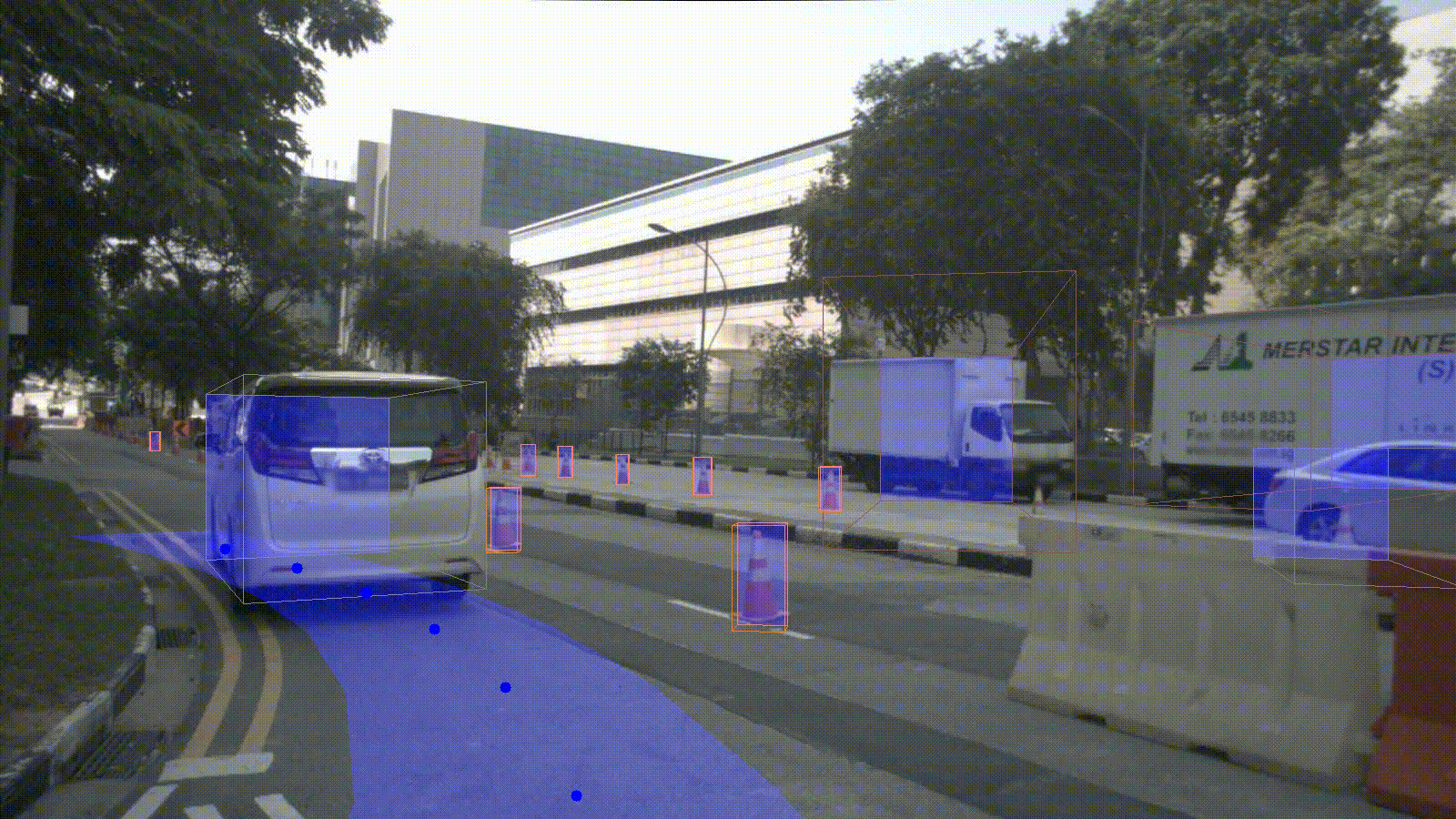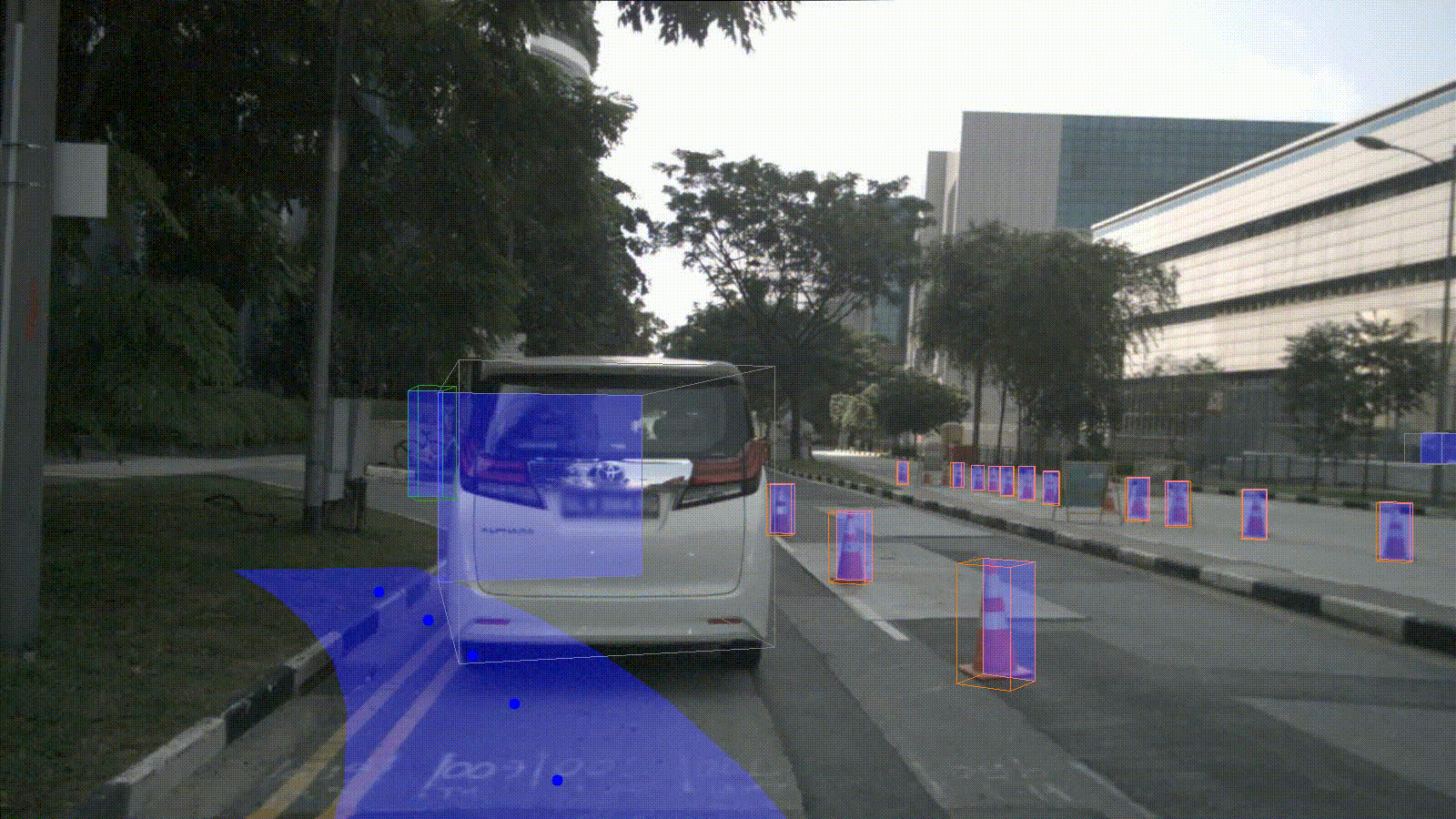


Installation
To get started with OpenEMMA, follow these steps to set up your environment and dependencies.
-
Environment Setup
Set up a Conda environment for OpenEMMA with Python 3.8:bashconda create -n openemma python=3.8 conda activate openemma -
Install OpenEMMA
You can now install OpenEMMA with a single command using PyPI:bashpip install openemmaAlternatively, follow these steps:
- Clone OpenEMMA Repository
Clone the OpenEMMA repository and navigate to the root directory:bashgit clone git@github.com:taco-group/OpenEMMA.git cd OpenEMMA - Install Dependencies
Ensure you have cudatoolkit installed. If not, use the following command:
To install the core packages required for OpenEMMA, run the following command:bashconda install nvidia/label/cuda-12.4.0::cuda-toolkit
This will install all dependencies, including those for YOLO-3D, an external tool used for critical object detection. The weights needed to run YOLO-3D will be automatically downloaded during the first execution.bashpip install -r requirements.txt
- Clone OpenEMMA Repository
-
Set up GPT-4 API Access
To enable GPT-4’s reasoning capabilities, obtain an API key from OpenAI. You can add your API key directly in the code where prompted or set it up as an environment variable:bashexport OPENAI_API_KEY="your_openai_api_key"This allows OpenEMMA to access GPT-4 for generating future waypoints and decision rationales.
Usage
After setting up the environment, you can start using OpenEMMA with the following instructions:
-
Prepare Input Data
Download and extract the nuScenes dataset -
Run OpenEMMA
Use the following command to execute OpenEMMA's main script:- PyPI:
bashopenemma \ --model-path qwen \ --dataroot [dir-of-nuScenes-dataset] \ --version [version-of-nuScenes-dataset] \ --method openemma- Github Repo:
bashpython main.py \ --model-path qwen \ --dataroot [dir-of-nuscnse-dataset] \ --version [version-of-nuscnse-dataset] \ --method openemmaCurrently, we support the following models:
GPT-4o,LLaVA-1.6-Mistral-7B,Llama-3.2-11B-Vision-Instruct, andQwen2-VL-7B-Instruct. To use a specific model, simply passgpt,llava,llama, andqwenas the argument to--model-path. -
Output Interpretation
After running the model, OpenEMMA generates the following output in the./qwen-resultslocation:-
Waypoints: A list of future waypoints predicting the ego vehicle’s trajectory.
-
Decision Rationales: Text explanations of the model’s reasoning, including scene context, critical objects, and behavior decisions.
-
Annotated Images: Visualizations of the planned trajectory and detected critical objects overlaid on the original images.
-
Compiled Video: A video (e.g.,
output_video.mp4) created from the annotated images, showing the predicted path over time.
-
Contact
For help or issues using this package, please submit a GitHub issue.
For personal communication related to this project, please contact Shuo Xing (shuoxing@tamu.edu).
Citation
We are more than happy if this code is helpful to your work.
If you use our code or extend our work, please consider citing our paper:
bibtex@article{openemma, author = {Xing, Shuo and Qian, Chengyuan and Wang, Yuping and Hua, Hongyuan and Tian, Kexin and Zhou, Yang and Tu, Zhengzhong}, title = {OpenEMMA: Open-Source Multimodal Model for End-to-End Autonomous Driving}, journal = {arXiv}, year = {2024}, month = dec, eprint = {2412.15208}, doi = {10.48550/arXiv.2412.15208} }
Contributors
Showing top 10 contributors by commit count.










Related Repositories

jwasham/coding-interview-university
A complete computer science study plan to become a software engineer.

trekhleb/javascript-algorithms
📝 Algorithms and data structures implemented in JavaScript with explanations and links to further readings

yangshun/tech-interview-handbook
Curated coding interview preparation materials for busy software engineers

labuladong/fucking-algorithm
Crack LeetCode, not only how, but also why.

krahets/hello-algo
《Hello 算法》:动画图解、一键运行的数据结构与算法教程。支持简中、繁中、English、日本語,提供 Python, Java, C++, C, C#, JS, Go, Swift, Rust, Ruby, Kotlin, TS, Dart 等代码实现

Developer-Y/cs-video-courses
List of Computer Science courses with video lectures.