PDVC
End-to-End Dense Video Captioning with Parallel Decoding (ICCV 2021)
Official implementation for End-to-End Dense Video Captioning with Parallel Decoding (ICCV 2021) The project is written primarily in Python, distributed under the MIT License license, first published in 2021. Key topics include: activitynet-captions, dense-video-captioning, video-paragraph-captioning, youcook2.
PDVC
Official implementation for End-to-End Dense Video Captioning with Parallel Decoding (ICCV 2021)
This repo supports:
- two video captioning tasks: dense video captioning and video paragraph captioning
- two datasets: ActivityNet Captions and YouCook2
- video features containing C3D, TSN, and TSP.
- visualization of the generated captions of your own videos
Table of Contents:
- Updates
- Introduction
- Preparation
- Running PDVC on Your Own Videos
- Training and Validation
- Performance
- Citation
- Acknowledgement
Updates
- (2021.11.19) add code for running PDVC on raw videos and visualize the generated captions (support Chinese and other non-English languages)
- (2021.11.19) add pretrained models with TSP features. It achieves 9.03 METEOR(2021) and 6.05 SODA_c, a very competitive result on ActivityNet Captions without self-critical sequence training.
- (2021.08.29) add TSN pretrained models and support YouCook2
Introduction
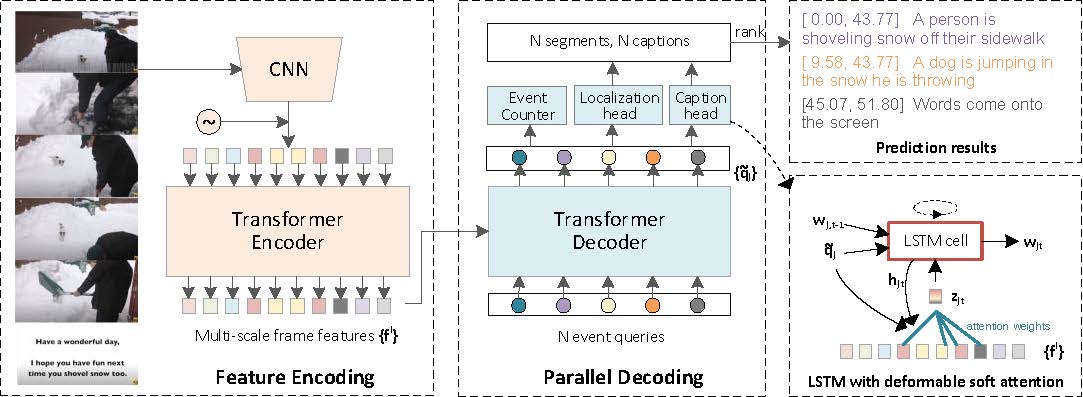
PDVC is a simple yet effective framework for end-to-end dense video captioning with parallel decoding (PDVC), by formulating the dense caption generation as a set prediction task. Without bells and whistles, extensive experiments on ActivityNet Captions and YouCook2 show that PDVC is capable of producing high-quality captioning results, surpassing the state-of-the-art methods when its localization accuracy is on par with them.
Preparation
Environment: Linux, GCC>=5.4, CUDA >= 9.2, Python>=3.7, PyTorch>=1.5.1
- Clone the repo
bashgit clone --recursive https://github.com/ttengwang/PDVC.git
- Create virtual environment by conda
bashconda create -n PDVC python=3.7 source activate PDVC conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=10.1 -c pytorch conda install ffmpeg pip install -r requirement.txt
- Compile the deformable attention layer (requires GCC >= 5.4).
bashcd pdvc/ops sh make.sh
Running PDVC on Your Own Videos
Download a pretrained model (GoogleDrive) with TSP features and put it into ./save. Then run:
bashvideo_folder=visualization/videos output_folder=visualization/output pdvc_model_path=save/anet_tsp_pdvc/model-best.pth output_language=en bash test_and_visualize.sh $video_folder $output_folder $pdvc_model_path $output_language
check the $output_folder, you will see a new video with embedded captions.
Note that we generate non-English captions by translating the English captions by GoogleTranslate.
To produce Chinese captions, set output_language=zh-cn.
For other language support, find the abbreviation of your language at this url, and you also may need to download a font supporting your language and put it into ./visualization.


Training and Validation
Download Video Features
bashcd data/anet/features bash download_anet_c3d.sh # bash download_anet_tsn.sh # bash download_i3d_vggish_features.sh # bash download_tsp_features.sh
The preprocessed C3D features have been uploaded to baiduyun drive
Dense Video Captioning
- PDVC with learnt proposals
# Training
config_path=cfgs/anet_c3d_pdvc.yml
python train.py --cfg_path ${config_path} --gpu_id ${GPU_ID}
# The script will evaluate the model for every epoch. The results and logs are saved in `./save`.
# Evaluation
eval_folder=anet_c3d_pdvc # specify the folder to be evaluated
python eval.py --eval_folder ${eval_folder} --eval_transformer_input_type queries --gpu_id ${GPU_ID}
- PDVC with ground-truth proposals
# Training
config_path=cfgs/anet_c3d_pdvc_gt.yml
python train.py --cfg_path ${config_path} --gpu_id ${GPU_ID}
# Evaluation
eval_folder=anet_c3d_pdvc_gt
python eval.py --eval_folder ${eval_folder} --eval_transformer_input_type gt_proposals --gpu_id ${GPU_ID}
Video Paragraph Captioning
- PDVC with learnt proposals
bash# Training config_path=cfgs/anet_c3d_pdvc.yml python train.py --cfg_path ${config_path} --criteria_for_best_ckpt pc --gpu_id ${GPU_ID} # Evaluation eval_folder=anet_c3d_pdvc # specify the folder to be evaluated python eval.py --eval_folder ${eval_folder} --eval_transformer_input_type queries --gpu_id ${GPU_ID}
- PDVC with ground-truth proposals
# Training
config_path=cfgs/anet_c3d_pdvc_gt.yml
python train.py --cfg_path ${config_path} --criteria_for_best_ckpt pc --gpu_id ${GPU_ID}
# Evaluation
eval_folder=anet_c3d_pdvc_gt
python eval.py --eval_folder ${eval_folder} --eval_transformer_input_type gt_proposals --gpu_id ${GPU_ID}
Performance
Dense video captioning (with learnt proposals)
| Model | Features | config_path | Url | Recall | Precision | BLEU4 | METEOR2018 | METEOR2021 | CIDEr | SODA_c |
|---|---|---|---|---|---|---|---|---|---|---|
| PDVC_light | C3D | cfgs/anet_c3d_pdvcl.yml | Google Drive | 55.30 | 58.42 | 1.55 | 7.13 | 7.66 | 24.80 | 5.23 |
| PDVC | C3D | cfgs/anet_c3d_pdvc.yml | Google Drive | 55.20 | 57.36 | 1.82 | 7.48 | 8.09 | 28.16 | 5.47 |
| PDVC_light | TSN | cfgs/anet_tsn_pdvcl.yml | Google Drive | 55.34 | 57.97 | 1.66 | 7.41 | 7.97 | 27.23 | 5.51 |
| PDVC | TSN | cfgs/anet_tsn_pdvc.yml | Google Drive | 56.21 | 57.46 | 1.92 | 8.00 | 8.63 | 29.00 | 5.68 |
| PDVC_light | TSP | cfgs/anet_tsp_pdvcl.yml | Google Drive | 55.24 | 57.78 | 1.77 | 7.94 | 8.55 | 28.25 | 5.95 |
| PDVC | TSP | cfgs/anet_tsp_pdvc.yml | Google Drive | 55.79 | 57.39 | 2.17 | 8.37 | 9.03 | 31.14 | 6.05 |
Notes:
- In the paper, we follow the most previous methods to use the evaluation toolkit in ActivityNet Challenge 2018. Note that the latest evluation tookit (METEOR2021) gives the same CIDEr/BLEU4 but a higher METEOR score.
- In the paper, we use an old version of SODA_c implementation, while here we use an updated version for convenience.
Video paragraph captioning (with learnt proposals)
| Model | Features | config_path | BLEU4 | METEOR | CIDEr |
|---|---|---|---|---|---|
| PDVC | C3D | cfgs/anet_c3d_pdvc.yml | 9.67 | 14.74 | 16.43 |
| PDVC | TSN | cfgs/anet_tsn_pdvc.yml | 10.18 | 15.96 | 20.66 |
| PDVC | TSP | cfgs/anet_tsp_pdvc.yml | 10.46 | 16.42 | 20.91 |
Notes:
- Paragraph-level scores are evaluated on the ActivityNet Entity ae-val set.
Citation
If you find this repo helpful, please consider citing:
@inproceedings{wang2021end,
title={End-to-End Dense Video Captioning with Parallel Decoding},
author={Wang, Teng and Zhang, Ruimao and Lu, Zhichao and Zheng, Feng and Cheng, Ran and Luo, Ping},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={6847--6857},
year={2021}
}
@ARTICLE{wang2021echr,
author={Wang, Teng and Zheng, Huicheng and Yu, Mingjing and Tian, Qian and Hu, Haifeng},
journal={IEEE Transactions on Circuits and Systems for Video Technology},
title={Event-Centric Hierarchical Representation for Dense Video Captioning},
year={2021},
volume={31},
number={5},
pages={1890-1900},
doi={10.1109/TCSVT.2020.3014606}}
Acknowledgement
The implementation of Deformable Transformer is mainly based on Deformable DETR.
The implementation of the captioning head is based on ImageCaptioning.pytorch.
We thanks the authors for their efforts.
Contributors
Showing top 1 contributor by commit count.

Related Repositories

v-iashin/BMT
Source code for "Bi-modal Transformer for Dense Video Captioning" (BMVC 2020)

jayleicn/recurrent-transformer
[ACL 2020] PyTorch code for MART: Memory-Augmented Recurrent Transformer for Coherent Video Paragraph Captioning
v-iashin/MDVC
PyTorch implementation of Multi-modal Dense Video Captioning (CVPR 2020 Workshops)

jssprz/video_captioning_datasets
Summary about Video-to-Text datasets. This repository is part of the review paper *Bridging Vision and Language from the Video-to-Text Perspective: A Comprehensive Review*

WuJie1010/Awesome-Temporally-Language-Grounding
A curated list of “Temporally Language Grounding” and related area
WuJie1010/Temporally-language-grounding
A Pytorch implemention for some state-of-the-art models for" Temporally Language Grounding in Untrimmed Videos"