Vaex
Out-of-Core hybrid Apache Arrow/NumPy DataFrame for Python, ML, visualization and exploration of big tabular data at a billion rows per second 🚀
Vaex is a high performance Python library for lazy **Out-of-Core DataFrames** (similar to Pandas), to visualize and explore big tabular datasets. It calculates *statistics* such as mean, sum, count, standard deviation etc, on an *N-dimensional grid* for more than **a billion** (`10^9`) samples/rows **per second**. Visualization is done using **histograms**, **density plots** and **3d volume rendering**, allowing interactive exploration of big data. Vaex uses memory mapping, zero memory copy poli... The project is written primarily in Python, distributed under the MIT License license, first published in 2014. It has gained significant community traction with 8,504 stars and 603 forks on GitHub. Key topics include: bigdata, data-science, dataframe, hdf5, machine-learning.
![]()

What is Vaex?
Vaex is a high performance Python library for lazy Out-of-Core DataFrames
(similar to Pandas), to visualize and explore big tabular datasets. It
calculates statistics such as mean, sum, count, standard deviation etc, on an
N-dimensional grid for more than a billion (10^9) samples/rows per
second. Visualization is done using histograms, density plots and 3d
volume rendering, allowing interactive exploration of big data. Vaex uses
memory mapping, zero memory copy policy and lazy computations for best
performance (no memory wasted).
Installing
With pip:
$ pip install vaex
Or conda:
$ conda install -c conda-forge vaex
For more details, see the documentation
Key features
Instant opening of Huge data files (memory mapping)
HDF5 and Apache Arrow supported.

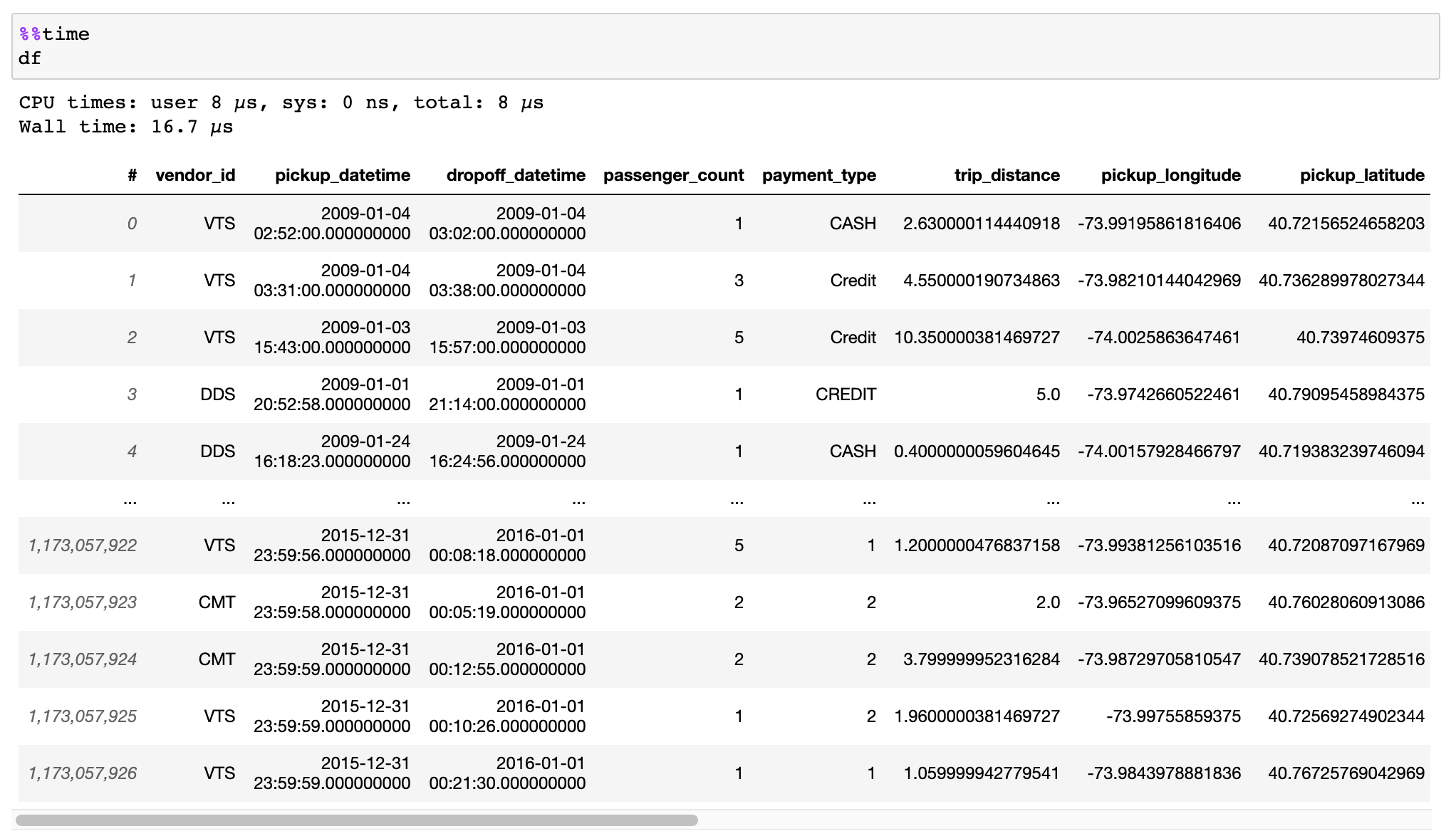
Read the documentation on how to efficiently convert your data from CSV files, Pandas DataFrames, or other sources.
Lazy streaming from S3 supported in combination with memory mapping.

Expression system
Don't waste memory or time with feature engineering, we (lazily) transform your data when needed.
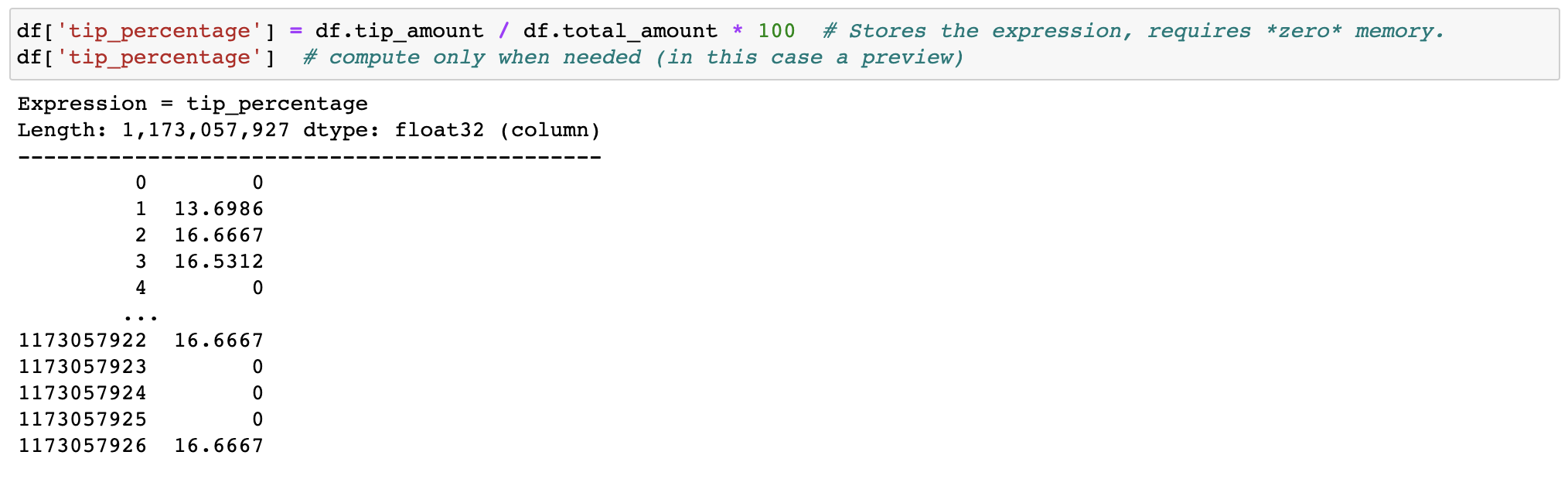
Out-of-core DataFrame
Filtering and evaluating expressions will not waste memory by making copies; the data is kept untouched on disk, and will be streamed only when needed. Delay the time before you need a cluster.

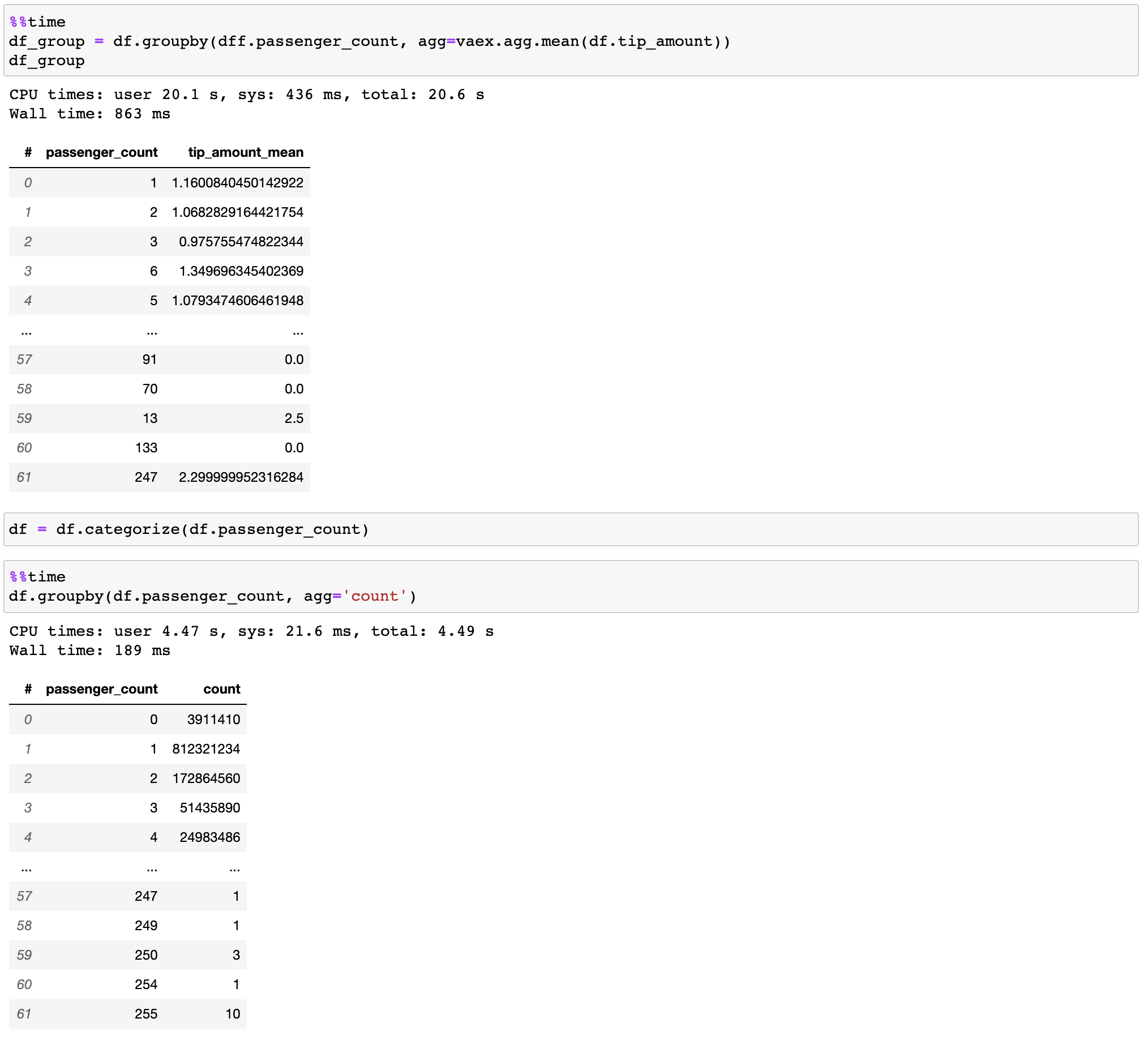
Fast groupby / aggregations
Vaex implements parallelized, highly performant groupby operations, especially when using categories (>1 billion/second).
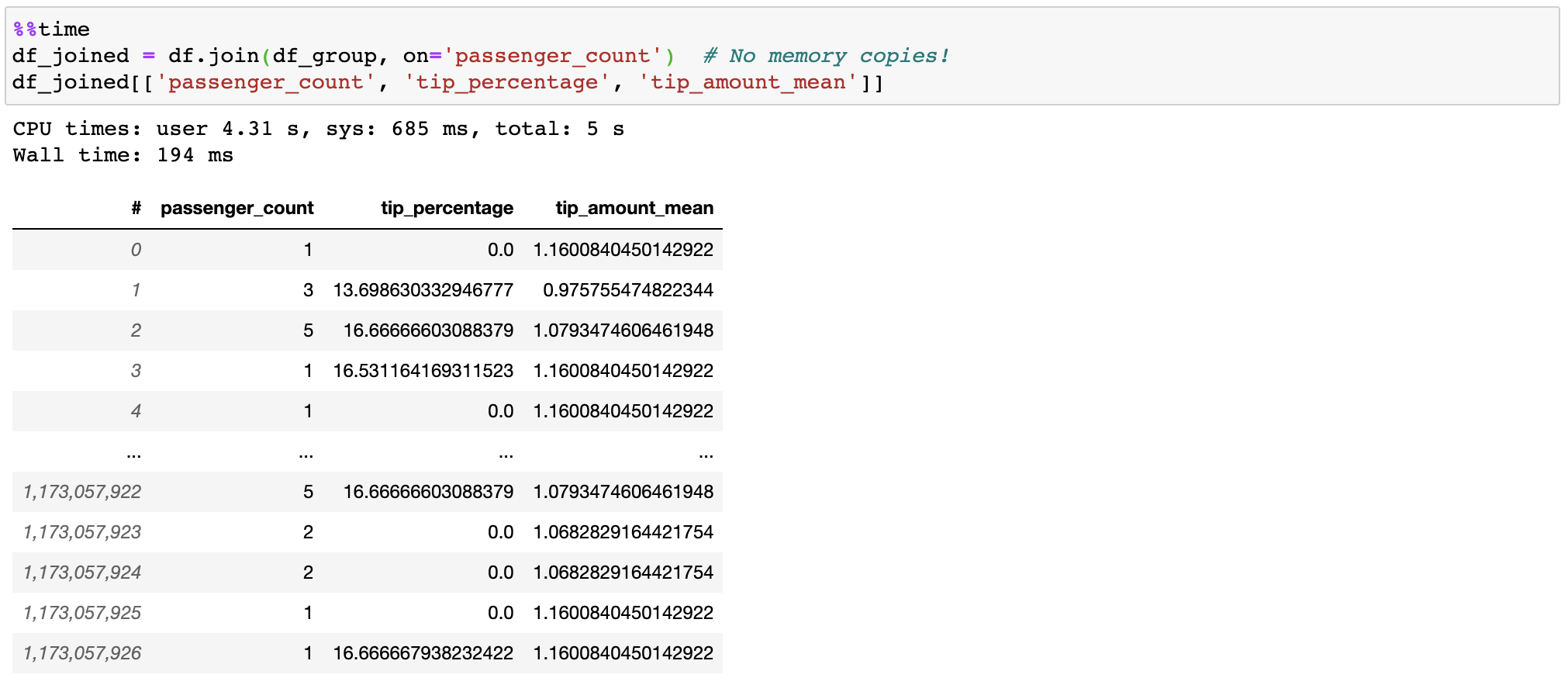
Fast and efficient join
Vaex doesn't copy/materialize the 'right' table when joining, saving gigabytes of memory. With subsecond joining on a billion rows, it's pretty fast!
More features
- Remote DataFrames (documentation coming soon)
- Integration into Jupyter and Voila for interactive notebooks and dashboards
- Machine Learning without (explicit) pipelines
Contributing
See contributing page.
Slack
Join the discussion in our Slack channel!
Learn more about Vaex
-
Articles
- Beyond Pandas: Spark, Dask, Vaex and other big data technologies battling head to head (includes benchmarks)
- 7 reasons why I love Vaex for data science (tips and trics)
- ML impossible: Train 1 billion samples in 5 minutes on your laptop using Vaex and Scikit-Learn
- How to analyse 100 GB of data on your laptop with Python
- Flying high with Vaex: analysis of over 30 years of flight data in Python
- Vaex: A DataFrame with super strings - Speed up your text processing up to a 1000x
- Vaex: Out of Core Dataframes for Python and Fast Visualization - 1 billion row datasets on your laptop
-
Watch our more recent talks:
-
Contact us for data science solutions, training, or enterprise support at https://vaex.io/
Contributors
Showing top 12 contributors by commit count.












Related Repositories

DataExpert-io/data-engineer-handbook
This is a repo with links to everything you'd ever want to learn about data engineering

rustfs/rustfs
🚀2.3x faster than MinIO for 4KB object payloads. RustFS is an open-source, S3-compatible high-performance object storage system supporting migration and coexistence with other S3-compatible platforms such as MinIO and Ceph.

taosdata/TDengine
High-performance, scalable time-series database designed for Industrial IoT (IIoT) scenarios

apache/shardingsphere
Empowering Data Intelligence with Distributed SQL for Sharding, Scalability, and Security Across All Databases.

heibaiying/BigData-Notes
大数据入门指南 :star:

oxnr/awesome-bigdata
A curated list of awesome big data frameworks, ressources and other awesomeness.