Ai simplest network
The simplest form of an artificial neural network explained and demonstrated.
This is the simplest artificial neural network possible explained and demonstrated. The project is written primarily in Go, first published in 2019. Key topics include: artificial-intelligence, artificial-neural-networks, golang, gradient-descent, machine-learning.
Simplest artificial neural network
This is the simplest artificial neural network possible explained and demonstrated.
This is part 1 of a series of github repos on neural networks
- part 1 - simplest network (you are here)
- part 2 - backpropagation
- part 3 - backpropagation-continued
Table of Contents
Theory
Mimicking neurons
Artificial neural networks are inspired by the brain by having interconnected artificial neurons store patterns and communicate with each other.
The simplest form of an artificial neuron has one or multiple inputs <img src="/tex/9fc20fb1d3825674c6a279cb0d5ca636.svg?invert_in_darkmode&sanitize=true" align=middle width=14.045887349999989pt height=14.15524440000002pt/> each having a specific weight <img src="/tex/c2a29561d89e139b3c7bffe51570c3ce.svg?invert_in_darkmode&sanitize=true" align=middle width=16.41940739999999pt height=14.15524440000002pt/> and one output <img src="/tex/deceeaf6940a8c7a5a02373728002b0f.svg?invert_in_darkmode&sanitize=true" align=middle width=8.649225749999989pt height=14.15524440000002pt/>.
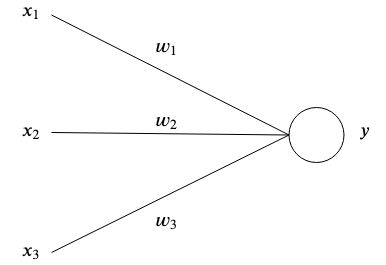
At the simplest level, the output is the sum of its inputs times its weights.
<p align="center"><img src="/tex/c2d2775d67e954682fac686e557baed2.svg?invert_in_darkmode&sanitize=true" align=middle width=88.33802834999999pt height=44.89738935pt/></p>A simple example
The purpose of a network is to learn a certain output <img src="/tex/deceeaf6940a8c7a5a02373728002b0f.svg?invert_in_darkmode&sanitize=true" align=middle width=8.649225749999989pt height=14.15524440000002pt/> given certain input(s) <img src="/tex/332cc365a4987aacce0ead01b8bdcc0b.svg?invert_in_darkmode&sanitize=true" align=middle width=9.39498779999999pt height=14.15524440000002pt/> by approximating a complex function with many parameters <img src="/tex/31fae8b8b78ebe01cbfbe2fe53832624.svg?invert_in_darkmode&sanitize=true" align=middle width=12.210846449999991pt height=14.15524440000002pt/> that we couldn't come up with ourselves.
Say we have a network with two inputs <img src="/tex/f9b6dcc9279f659321ac3e1098b0ba4f.svg?invert_in_darkmode&sanitize=true" align=middle width=59.69172164999999pt height=21.18721440000001pt/> and <img src="/tex/bf84a893effff44b6d014b2b60460585.svg?invert_in_darkmode&sanitize=true" align=middle width=59.69172164999999pt height=21.18721440000001pt/> and two weights <img src="/tex/4b4518f1b7f0fb1347fa21506ebafb19.svg?invert_in_darkmode&sanitize=true" align=middle width=18.32105549999999pt height=14.15524440000002pt/> and <img src="/tex/f7eb0e840408d84a0c156d6efb611f3e.svg?invert_in_darkmode&sanitize=true" align=middle width=18.32105549999999pt height=14.15524440000002pt/>.
The idea is to adjust the weights in such a way that the given inputs produce the desired output.
Weights are normally initialized randomly since we can't know their optimal value ahead of time, however for simplicity we will initialize them both to <img src="/tex/034d0a6be0424bffe9a6e7ac9236c0f5.svg?invert_in_darkmode&sanitize=true" align=middle width=8.219209349999991pt height=21.18721440000001pt/>.
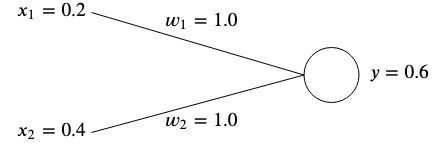
If we calculate the output of this network, we will get
<p align="center"><img src="/tex/48c4f6073c4655b74cebf396493c9228.svg?invert_in_darkmode&sanitize=true" align=middle width=322.4824614pt height=13.789957499999998pt/></p>The error
If the output <img src="/tex/deceeaf6940a8c7a5a02373728002b0f.svg?invert_in_darkmode&sanitize=true" align=middle width=8.649225749999989pt height=14.15524440000002pt/> doesn't match the expected target value, then we have an error.
For example, if we wanted to get a target value of <img src="/tex/72dd6f18a88876a3e9697d3cd247d0b8.svg?invert_in_darkmode&sanitize=true" align=middle width=48.858371099999985pt height=21.18721440000001pt/> then we would have a difference of
One common way to measure the error (also referred to as the cost function) is to use the mean squared error:
<p align="center"><img src="/tex/f9a1a3500d0047642b9e0aa44e315d61.svg?invert_in_darkmode&sanitize=true" align=middle width=101.17868145pt height=32.990165999999995pt/></p>If we had multiple associations of inputs and target values, then the error becomes the average sum of each association.
<p align="center"><img src="/tex/0b27b4f92bb0aa649d3980861c413f8b.svg?invert_in_darkmode&sanitize=true" align=middle width=147.88537499999998pt height=44.89738935pt/></p>We use the mean squared error to measure how far away the results are from our desired target. The squaring removes negative signs and gives more weight to bigger differences between output and target.
To rectify the error, we would need to adjust the weights in a way that the output matches our target. In our example, lowering <img src="/tex/4b4518f1b7f0fb1347fa21506ebafb19.svg?invert_in_darkmode&sanitize=true" align=middle width=18.32105549999999pt height=14.15524440000002pt/> from <img src="/tex/f58ed17486d1735419372f2b7d091779.svg?invert_in_darkmode&sanitize=true" align=middle width=21.00464354999999pt height=21.18721440000001pt/> to <img src="/tex/cde2d598001a947a6afd044a43d15629.svg?invert_in_darkmode&sanitize=true" align=middle width=21.00464354999999pt height=21.18721440000001pt/> would do the trick, since
<p align="center"><img src="/tex/385570808d7e0408dd491b7647e205de.svg?invert_in_darkmode&sanitize=true" align=middle width=236.5025355pt height=13.789957499999998pt/></p>However, in order to adjust the weights of our neural networks for many different inputs and target values, we need a learning algorithm to do this for us automatically.
Gradient descent
The idea is to use the error to understand how each weight should be adjusted so that the error is minimized, but first, we need to learn about gradients.
What is a gradient?
It's essentially a vector pointing to the direction of the steepest ascent of a function. The gradient is denoted with <img src="/tex/47c28f1929c18f887420345e9225e08b.svg?invert_in_darkmode&sanitize=true" align=middle width=13.69867124999999pt height=22.465723500000017pt/> and is simply the partial derivative of each variable of a function expressed as a vector.
It looks like this for a two variable function:
<p align="center"><img src="/tex/b142e84f3f77e6dc3144eb723cd4510d.svg?invert_in_darkmode&sanitize=true" align=middle width=303.75993285pt height=37.9216761pt/></p>Let's inject some numbers and calculate the gradient with a simple example.
Say we have a function <img src="/tex/8f41fe11e0e63d98f2fe17a78df752c8.svg?invert_in_darkmode&sanitize=true" align=middle width=138.37136445pt height=26.76175259999998pt/>, then the gradient would be
What is gradient descent?
The descent part simply means using the gradient to find the direction of steepest ascent of our function and then going in the opposite direction by a small amount many times to find the function global (or sometimes local) minimum.
We use a constant called the learning rate, denoted with <img src="/tex/7ccca27b5ccc533a2dd72dc6fa28ed84.svg?invert_in_darkmode&sanitize=true" align=middle width=6.672392099999992pt height=14.15524440000002pt/> to define how small of a step to take in that direction.
If <img src="/tex/7ccca27b5ccc533a2dd72dc6fa28ed84.svg?invert_in_darkmode&sanitize=true" align=middle width=6.672392099999992pt height=14.15524440000002pt/> is too large, then we risk overshooting the function minimum, but if it's too low then the network will take longer to learn and we risk getting stuck in a shallow local minimum.
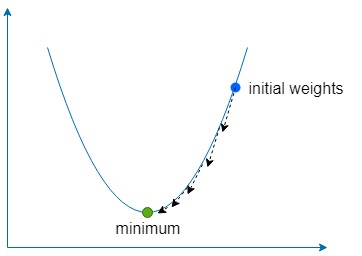
Gradient descent applied to our example network
For our two weights <img src="/tex/4b4518f1b7f0fb1347fa21506ebafb19.svg?invert_in_darkmode&sanitize=true" align=middle width=18.32105549999999pt height=14.15524440000002pt/> and <img src="/tex/f7eb0e840408d84a0c156d6efb611f3e.svg?invert_in_darkmode&sanitize=true" align=middle width=18.32105549999999pt height=14.15524440000002pt/> we need to find the gradient of those weights with respect to the error function <img src="/tex/84df98c65d88c6adf15d4645ffa25e47.svg?invert_in_darkmode&sanitize=true" align=middle width=13.08219659999999pt height=22.465723500000017pt/>
<p align="center"><img src="/tex/912be46ac0db99c8544f0800527d4b9f.svg?invert_in_darkmode&sanitize=true" align=middle width=147.62782815pt height=36.2778141pt/></p>For both <img src="/tex/4b4518f1b7f0fb1347fa21506ebafb19.svg?invert_in_darkmode&sanitize=true" align=middle width=18.32105549999999pt height=14.15524440000002pt/> and <img src="/tex/f7eb0e840408d84a0c156d6efb611f3e.svg?invert_in_darkmode&sanitize=true" align=middle width=18.32105549999999pt height=14.15524440000002pt/>, we can find the gradient by using the chain rule
<p align="center"><img src="/tex/8d7dec910e58764e57aa27f328a7396c.svg?invert_in_darkmode&sanitize=true" align=middle width=570.4098938999999pt height=39.452455349999994pt/></p>From now on we will denote the <img src="/tex/053259646a84530b56faa65084783f24.svg?invert_in_darkmode&sanitize=true" align=middle width=76.5775791pt height=28.92634470000001pt/> as the <img src="/tex/38f1e2a089e53d5c990a82f284948953.svg?invert_in_darkmode&sanitize=true" align=middle width=7.928075099999989pt height=22.831056599999986pt/> term for simplicity.
Once we have the gradient, we can update our weights by subtracting the calculated gradient times the learning rate.
<p align="center"><img src="/tex/f46613c78403dce8eed0b6093ff36d28.svg?invert_in_darkmode&sanitize=true" align=middle width=222.19498950000002pt height=15.52509255pt/></p> <p align="center"><img src="/tex/223d39de0113b6136f26962ed907c8aa.svg?invert_in_darkmode&sanitize=true" align=middle width=222.19498950000002pt height=15.52509255pt/></p>And we repeat this process until the error is minimized and is close enough to zero.
Code example
The included example teaches the following dataset to a neural network with two inputs and one output using gradient descent:
<p align="center"><img src="/tex/0cdd43e831c22b1560861b7a3e660010.svg?invert_in_darkmode&sanitize=true" align=middle width=233.52364695pt height=39.452455349999994pt/></p>Once learned, the network should output ~0 when given two <img src="/tex/034d0a6be0424bffe9a6e7ac9236c0f5.svg?invert_in_darkmode&sanitize=true" align=middle width=8.219209349999991pt height=21.18721440000001pt/>s and ~<img src="/tex/034d0a6be0424bffe9a6e7ac9236c0f5.svg?invert_in_darkmode&sanitize=true" align=middle width=8.219209349999991pt height=21.18721440000001pt/> when given a <img src="/tex/034d0a6be0424bffe9a6e7ac9236c0f5.svg?invert_in_darkmode&sanitize=true" align=middle width=8.219209349999991pt height=21.18721440000001pt/> and a <img src="/tex/29632a9bf827ce0200454dd32fc3be82.svg?invert_in_darkmode&sanitize=true" align=middle width=8.219209349999991pt height=21.18721440000001pt/>.
How to run
Online on repl.it
Docker
bashdocker build -t simplest-network . docker run --rm simplest-network
References
- Artificial intelligence engines by James V Stone (2019)
- Complete guide on deep learning: http://neuralnetworksanddeeplearning.com/chap2.html
Contributors
Showing top 3 contributors by commit count.

![texify[bot]](https://avatars.githubusercontent.com/in/4219?v=4)

Related Repositories

Significant-Gravitas/AutoGPT
AutoGPT is the vision of accessible AI for everyone, to use and to build on. Our mission is to provide the tools, so that you can focus on what matters.

f/prompts.chat
f.k.a. Awesome ChatGPT Prompts. Share, discover, and collect prompts from the community. Free and open source — self-host for your organization with complete privacy.

rasbt/LLMs-from-scratch
Implement a ChatGPT-like LLM in PyTorch from scratch, step by step

hacksider/Deep-Live-Cam
real time face swap and one-click video deepfake with only a single image

thedotmack/claude-mem
Persistent Context Across Sessions for Every Agent – Captures everything your agent does during sessions, compresses it with AI, and injects relevant context back into future sessions. Works with Claude Code, OpenClaw, Codex, Gemini, Hermes, Copilot, OpenCode + More

OpenHands/OpenHands
🙌 OpenHands: AI-Driven Development